แนวทางการออกแบบ architecture สำหรับ workload ที่ write เยอะ ๆ
อาทิตย์นี้ได้มีโอกาสในการลองออกแบบ architecture สำหรับ workload ที่มี write operation (เช่น create, update) เยอะ ๆ พร้อมกันทีเดียว เช่น รับข้อมูลเข้ามาแบบ batch เป็น daily ที่มี record เป็นแสน-ล้าน ซึ่งเอาจริง ๆ เราก็รู้อยู่แล้วว่ามันมี know-how อยู่ด้วยกันหลัก ๆ 3 รูปแบบ ได้แก่
1. นำ component ที่รองรับการ write ได้สูงมาคั่น
Component ที่รองรับการ write ได้สูงมีด้วยกันหลายตัว เช่น
- Message queue เช่น RabbitMQ, ZeroMQ เป็นต้น
- Streaming processing engine เช่น pub-sub, Apache Kafka เป็น
- Distributed file/object system เช่น AWS S3, Apache Hadoop เป็นต้น
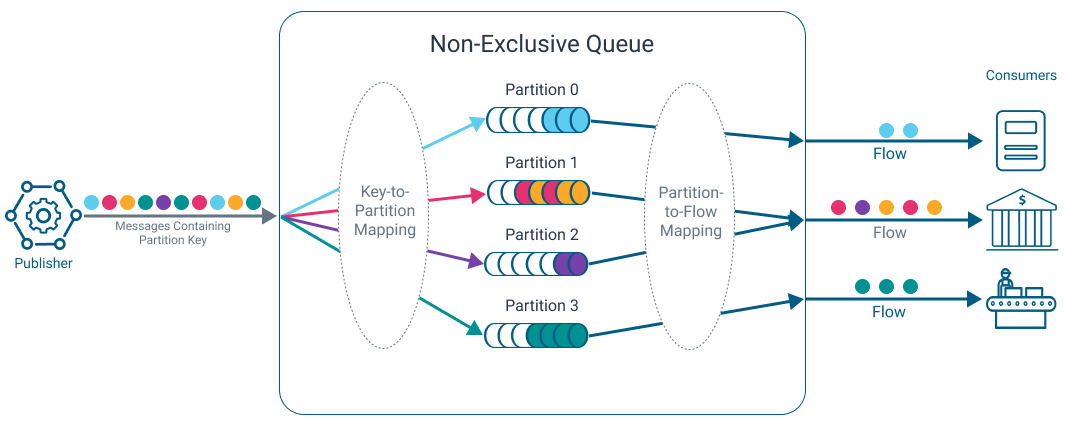
https://docs.solace.com/Messaging/Guaranteed-Msg/Partitioned-Queue-Messaging.htm
ในเชิง concept แล้ว component เหล่านี้มีสิ่งที่เหมือนกันคือข้างในมันก็เป็น server หลาย ๆ ตัวที่มี disk หลาย ๆ อัน (แต่ละเจ้าจะเรียกสิ่งเหล่านี้ต่างกันไป เช่น partitioning เป็นต้น) ทำให้เราสามารถ write ข้อมูลไปได้พร้อมกันหลาย ๆ ที่กระจายกันไป และจะมีการันตีว่าหลัง write ไปแล้วข้อมูลจะไม่สูญหายไปหากเกิดปัญหาต่าง ๆ เช่น server crash เป็นต้น
ปัญหาถัดไปที่เราต้องจัดการต่อคือ เราไม่สามารถการันตีลำดับของข้อมูลได้เพราะข้อมูลได้ถูกกระจายไปหลาย ๆ server ยกเว้นว่าเราจะตั้งไส้ในของมันให้มีแค่ 1 server เท่านั้น (ซึ่งก็ไม่ตอบโจทย์ตั้งต้นของบทความนี้ แต่ต่อให้มี 1 ตัวก็อาจจะเกิดปัญหาจากฝั่ง producer ก็ได้เพราะความเร็ว network ของแต่ละ producer อาจจะไม่เท่ากัน) ดังนั้นในฝั่ง consumer ข้างหลังต้องหาวิธีในการจัดการกับลำดับของข้อมูลเอง ซึ่งก็มีหลายท่า เช่น การใช้ timestamp, event sourcing ไม่ก็มี business process ในการทำ reconcilation ทีหลังก็ได้
เราสามารถกำหนดในฝั่ง consumer ของ component ได้ว่าในช่วงเวลานึงจะ consume ข้อมูลครั้งละเท่าไร ทำให้ traffic ไม่วิ่งเข้าไปที่ database มากเกินไป ซึ่งตรงนี้เราก็ต้องคำนวนและปรับ tune ให้มันไม่ไปติดคอขวดที่ database อีก
2. การทำ database sharding
ปัญหาที่หลาย ๆ ระบบมักจะเจอคือมีการทำ scale ในฝั่ง application server อย่างดี เช่น ติดตั้ง autoscaler จาก CPU/memory ที่สูงเกินกำหนด หรือแม้่แต่เกิด event บางอย่างขึ้น เป็นต้น แต่ไม่ได้ scale ในฝั่ง database ให้เพียงพอด้วย ทำให้สุดท้ายแล้วกลายเป็นซ้ำเดิมคอขวดที่มีอยู่แล้วให้หนักขึ้นไปอีก และระบบจะล่มเพราะจำนวนของ database connection เต็ม
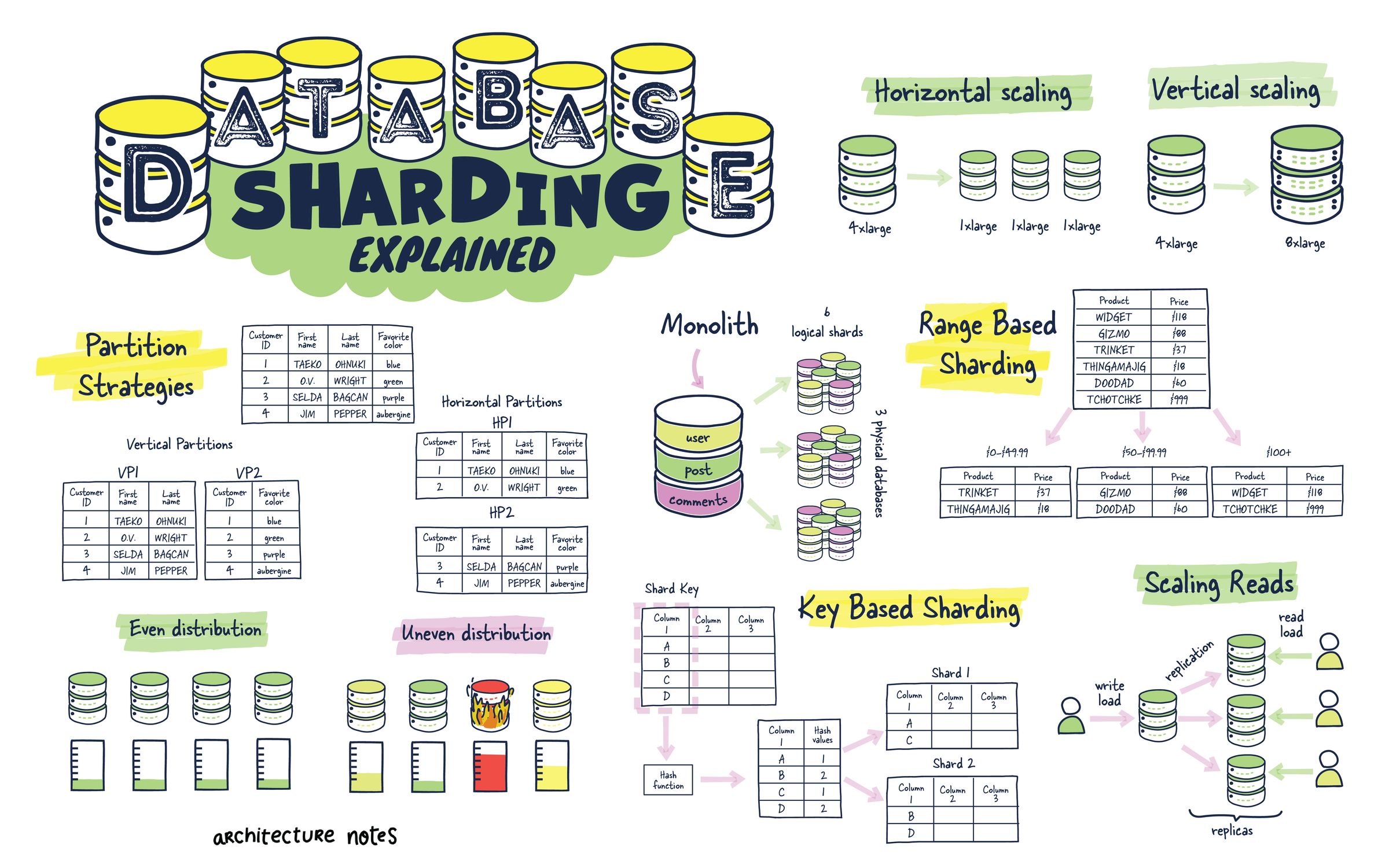
https://architecturenotes.co/database-sharding-explained/
เราสามารถทำ sharding ได้ กล่าวคือ scale database logical model (schema และ relationship) เดียวออกไปหลาย ๆ instance (เรียก instance เหล่านั้นว่า shard) ทำให้เราสามารถเก็บและ write database แยกออกไปหลาย ๆ server หลาย ๆ disk ได้ ส่วน database แต่ละเจ้าก็จะมีกลไกในการทำ routing ไปเก็บให้ถูก shard และวิธีการ shard อย่างเช่น key, range, hash ต่างกันไป
ซึ่งวิธีการ shard ก็เป็นหนึ่งในข้อจำกัด เพราะหากเราเลือกผิดวิธี เช่น เลือก shard key ไม่เหมาะสม ทำให้ข้อมูลกระจุกในบาง shard แทนที่จะกระจาย แน่นอนว่ามันยากที่จะเลือกได้ถูกตั้งแต่ครั้งแรกจึงต้องมีการ re-shard ตามมา ซึ่งก็จะกินเวลาและ resource มาก ส่งผลให้ต้องปิดระบบไปชั่วคราว กระทบกับผู้ใช้งานตรง ๆ นอกจากนี้ค่าใช้จ่ายในการ monitoring และ backup ย่อมสูงขึ้นตามไปด้วย
3. การกำหนด rate limiting/throttling ใน process ที่มารับ request
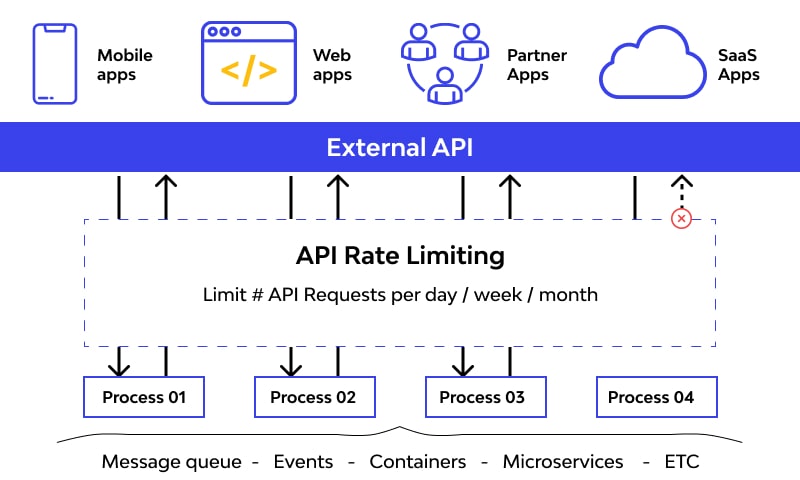
https://www.wallarm.com/what/rate-limiting
การทำ 2 วิธีข้างบนจะมีค่าใช้จ่ายด้าน infrastructure และการดูแลรักษาเพิ่มขึ้น ถ้าเราต้องออกแบบระบบที่มีข้อจำกัดด้านนี้สูงจนต่อรองไม่ได้ วิธีสุดท้ายคือลด traffic จากขาเข้าลง โดยใช้ technique อย่าง rate limiting (ดักในฝั่ง client) หรือ throttling (ดักในฝั่ง server) เพื่อจำกัดจำนวน request ที่ใช้ในการรับลง แต่ก็ต้องแลกกับความซับซ้อนในกรณีที่ limit ต่างกันในแต่ละ client และ user experience ที่อาจจะตกลงเพราะรับ request ได้ช้าลง
หากเรามาดูกันจริง ๆ แล้วแม้ว่ามันจะมีวิธีและเครื่องมือต่างกันไปมากมาย แต่ในเชิง concept นั้นมันเหมือนกัน คือ ไม่ลดจำนวนการ write ลงในช่วงเวลานึง ก็เอาลงไป write ในหลาย ๆ ที่แทน แลกกับความซับซ้อนในการจัดการ consistency และการดูแลรักษาในกรณีที่ระบบเกิดปัญหาสูงขึ้นในเชิง technical ที่ตอบโจทย์กับฝั่ง business