แบ่งปันแนวทางการป้องกัน PII บน database ด้วย data masking ฉบับปี 2022
PII คืออะไร ทำไมต้องป้องกันด้วย
ในการพัฒนา software ปัจจุบัน เรื่องของ security เป็นสิ่งที่จำเป็นต้องทุกระบบ ซึ่งแต่ละระบบก็จะมีการออกแบบและพัฒนาเพื่อปิดช่องโหว่จากการโจมตีผ่านสิ่งต่าง ๆ เช่น
- Dependencies เช่น library, framework, extension
- Secret เช่น password, API key
- Authentication & authorization
- Logging & monitoring
- Infrastructure
- Identity & access
หนึ่งในสิ่งที่เราต้องปกป้องก็คือ ข้อมูลส่วนบุคคลที่เมื่อรู้แล้วจะสามารถระบุตัวตนคน ๆ นั้นได้ (Personal Identifiable Information หรือ PII) เพราะถ้าข้อมูลหลุดออกไปแล้ว ผู้ไม่หวังดีก็มีโอกาสจะนำข้อมูลไปใช้ในทางที่ผิด นอกจากนั้นยังส่งผลเสียต่อบริษัท ทั้งด้านชื่อเสียง แม้กระทั่งเงิน ในกรณีที่เกิดการฟ้องร้องกัน
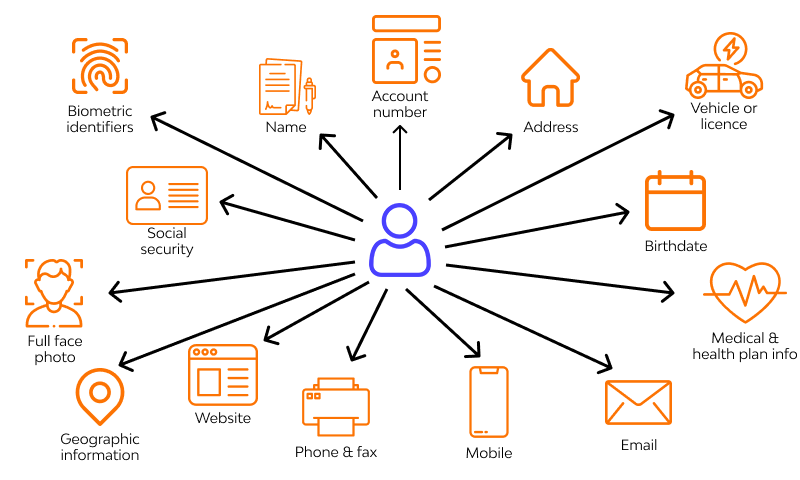 Securing PII In Web Applications
Securing PII In Web Applications
ระบบปัจจุบัน
ปัจจุบัน ทุกคนในทีมสามารถเข้าถึง database ได้ด้วย master user password ผ่าน bastion host โดยที่ใน bastion host จะมีการกำหนด access เป็นรายคนไปเลยผ่านการใช้ SSH ซึ่งคนที่จะเข้าได้จะต้องมาสร้าง system user พร้อม public key ใน bastion host
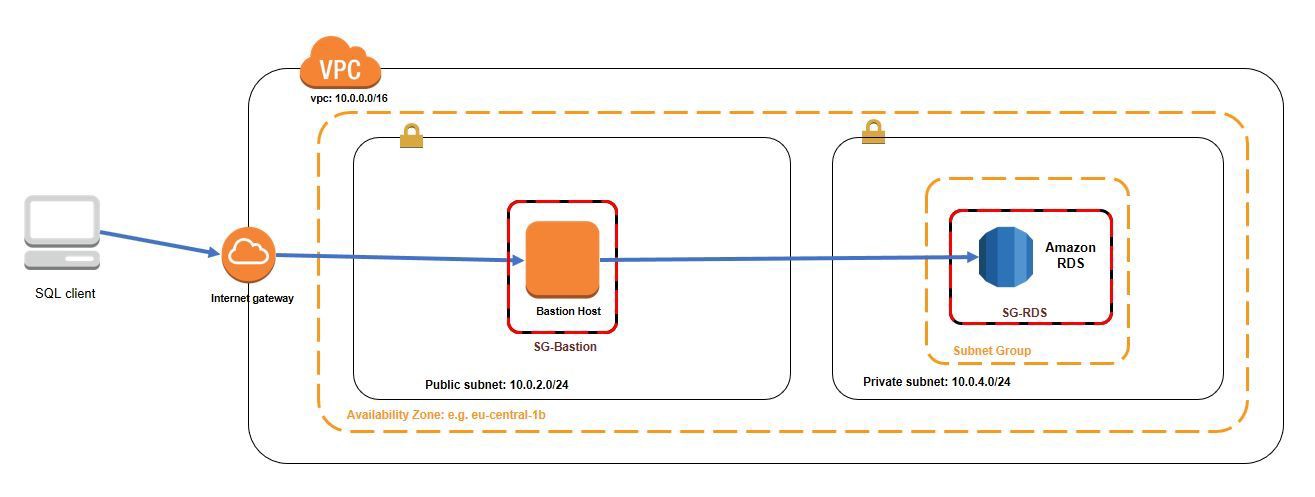
ต่อมา ประเทศสารขัณฑ์ (สมมติ) ออกกฎหมายว่าคนในทีมที่ไม่ได้อยู่ในประเทศสารขัณฑ์ จะไม่สามารถเข้าถึง PII ได้ แต่จากระบบปัจจุบัน จะเห็นว่าทุกคนยังมีสิทธิ์เห็น PII อยู่ ด้วยเหตุนี้เรามาทำการป้องกัน PII บน database กัน
วิธีทำ
เริ่มจากการแยก database user สำหรับประเทศสารขัณฑ์ออกจาก user ประเทศอื่นก่อน (ตัวอย่างจะตั้งชื่อว่า non_pii) จากนั้นก็ทำการแยก bastion host ออกด้วย เมื่อมีการเพิ่มหรือลบ system user ใน bastion host จะตรวจสอบได้ง่ายว่า user นั้นมีสิทธิ์เข้า PII ไหม
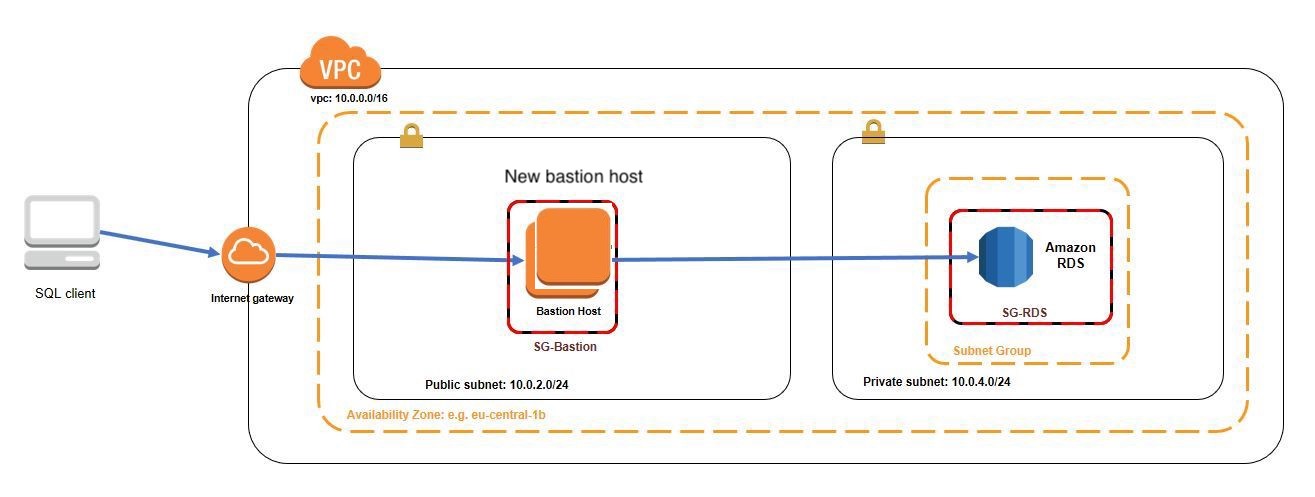
จากนั้น reset password ของ user ที่ใช้ login เข้า และซ่อน password ใหม่ไว้ไม่ให้คนที่ไม่ได้อยู่ในประเทศสารขัณฑ์เห็น ระวังเรื่อง downtime ที่อาจจะเกิดขึ้นใน application ที่เชื่อมต่อกับ database ด้วยนะ
สำหรับใน database หนึ่งใน technique ที่เราสามารถทำได้คือ data masking ซึ่งคือการแปลง PII ให้กลายเป็นข้อมูลปลอม ที่ไม่สามารถทำให้ผู้ไม่หวังดีเอาไปใช้งานต่อได้ เช่น เปลี่ยนข้อมูลเป็น hardcode เช่น *** หรือ สลับตำแหน่งตัวอักษรในข้อมูล หรือแม้กระทั่งสุ่มตัวอักษร โดยในบทความนี้จะมี 4 วิธีด้วยกัน มาดูกันว่ามีอะไรบ้าง
วิธีที่ 1: ใช้ database extension
ใน database เจ้าดัง ๆ ก็จะมี extension ในการทำ data masking อยู่แล้ว เช่น
- MySQL Enterprise Data Masking and De-Identification
- PostgreSQL Anonymizer
- SQL Server’s Dynamic Data Masking
ขั้นตอนที่ extension เหล่านี้ใช้คือ เราจะต้องสร้าง user และ role สำหรับทำ data masking ก่อน จากนั้นตั้ง rule ว่าจะ mask ด้วย technique ต่าง ๆ (สุ่ม สลับ) กับ table ไหนใน schema บ้าง ตัวอย่างของ PostgreSQL Anonymizer อย่างเช่น
ผลลัพธ์ก็จะได้ข้อมูลแบบ mask แค่บางส่วน (partial) เช่น 0812345678 -> 08*******8
ข้อดี
- รองรับ technique การทำ data masking แบบต่าง ๆ (สุ่ม สลับ)
- Open-source เราได้ update มี feature ใหม่ ๆ จาก community
ข้อเสีย
- บาง extension อาจจะไม่รองรับ database platform อย่าง Amazon Relational Database Service (RDS) อาจจะต้องติดตั้งด้วยวิธีอื่นนอกตำรา
วิธีที่ 2: ซ่อน column
วิธีนี้เราจะซ่อน column ที่มี PII ไปเลย โดยมีขั้นตอนดังนี้
- แยก database user สำหรับประเทศสารขัณฑ์ออกจาก user ประเทศอื่นก่อน (ตัวอย่างจะตั้งชื่อว่า
non_pii) - ใน
non_piiuser ให้สิทธิ์ในการใช้งาน database บน schema ตามต้องการ แต่จะยกเว้นส่วนในการเข้าไป read-write table ที่มี PII - ใน
non_piiuser ให้สิทธิ์ในการ read table column ที่ไม่ใช่ PII
ข้อดี
- เรียบง่าย แต่ใช้ได้จริง
ข้อเสีย
- ไม่สามารถทำอะไรกับ column ที่มี PII ได้ คนใช้ต้องรู้ว่ามันมี column นั้นอยู่เอง ดังนั้นก็จะลำบากในการเตรียมข้อมูลเพิ่มเองถ้าเอาข้อมูลไปทำอย่างอื่นด้วย
วิธีที่ 3: ซ่อน column และแสดงด้วย view ใน schema ใหม่
วิธีนี้จะต่อยอดจากวิธีที่ 2 เพื่อให้เราเห็น column ที่มี PII โดยมีขั้นตอนดังนี้
- แยก database user สำหรับประเทศสารขัณฑ์ออกจาก user ประเทศอื่นก่อน (ตัวอย่างจะตั้งชื่อว่า
non_pii) - ใน
non_piiuser ให้สิทธิ์ในการใช้งาน database บน schema ตามต้องการ แต่จะยกเว้นส่วนในการเข้าไป read-write table ที่มี PII - ใน
non_piiuser ให้สิทธิ์ในการ read table column ที่ไม่ใช่ PII - สร้าง schema ใหม่เพิ่มขึ้นมา (ตัวอย่างจะตั้งชื่อว่า
masked) - ใน schema
maskedทำการสร้าง view ใหม่ ที่มีโครงเหมือนกับ table ต้นฉบับ โดยแนะนำให้ตั้งชื่อเหมือนกับ table ต้นฉบับด้วย (ดูสาเหตุที่ข้อ 7) ในส่วนของการ masking เราสามารถ mask column นั้นผ่าน script ได้เลย (อาจจะเป็น constant หรือ สุ่มเอาก็ได้) - ใน
non_piiuser ให้สิทธิ์ในการเข้าถึง view ใหม่ - เพื่อง่ายต่อการใช้ SQL โดยไม่ต้องระบุ schema ให้ปรับลำดับของ schema ที่ใช้ในการ query (ตัวอย่างใน PostgreSQL จะต้องแก้ที่
search_path) เป็นสาเหตุว่าทำไมถึงแนะนำให้ตั้งชื่อ view ให้เหมือนกับ table ต้นฉบับนั่นเอง
ข้อดี
- สามารถเห็น column ครบตามต้องการ เข้าใจ data มากขึ้น
- สามารถใช้งาน operation อย่าง
SELECT *ได้
ข้อเสีย
- มีค่าใช้จ่ายในการดูแลรักษา หากมีการเปลี่ยนแปลงที่ table ต้นฉบับ จะต้องกลับมา update view ด้วย
วิธีที่ 4: ใช้เครื่องมือ third party
ในกรณีที่ database ของเราอยู่บน cloud เราสามารถใช้เครื่องมือต่าง ๆ มาช่วยทำ data masking ได้ เช่น
ข้อดี
- ค่าใช้จ่ายในการติดตั้งน้อยกว่าวิธีอื่น ๆ
ข้อเสีย
- ไม่ฟรี
- มีโอกาสที่ third party จะปล่อยข้อมูลรั่วไหล
- ต้องใช้เครื่องมือนี้ในการเข้า database หมายความว่าเราสามารถเข้าไปดู PII ได้อยู่ ถ้าไม่จำกัดเครื่องมือในการใช้งาน
จะเห็นว่าเรามีหลายวิธีให้เลือกพิจารณา มีข้อดี-ข้อเสียแตกต่างกันไป ลองนำไปปรับใช้ดูกันครับ