จดคำถามจาก session Data Mesh: A paradigm shift towards Domain Oriented Data Platform
เมื่อวันก่อนได้มีโอกาสเข้าไปฟัง webinar ในหัวข้อ Data Mesh: A paradigm shift towards Domain Oriented Data Platform โดยคุณ Zhamak Dehghani และ Brandon Byars จาก ThoughtWorks ซึ่งเกี่ยวกับการจัดการข้อมูลแบบ Big Data ในระบบ Distributed architecture เป็นหัวข้อใหม่(?)ที่ถูกพูดถึงครั้งแรกเมื่อปีที่แล้วนี่เอง
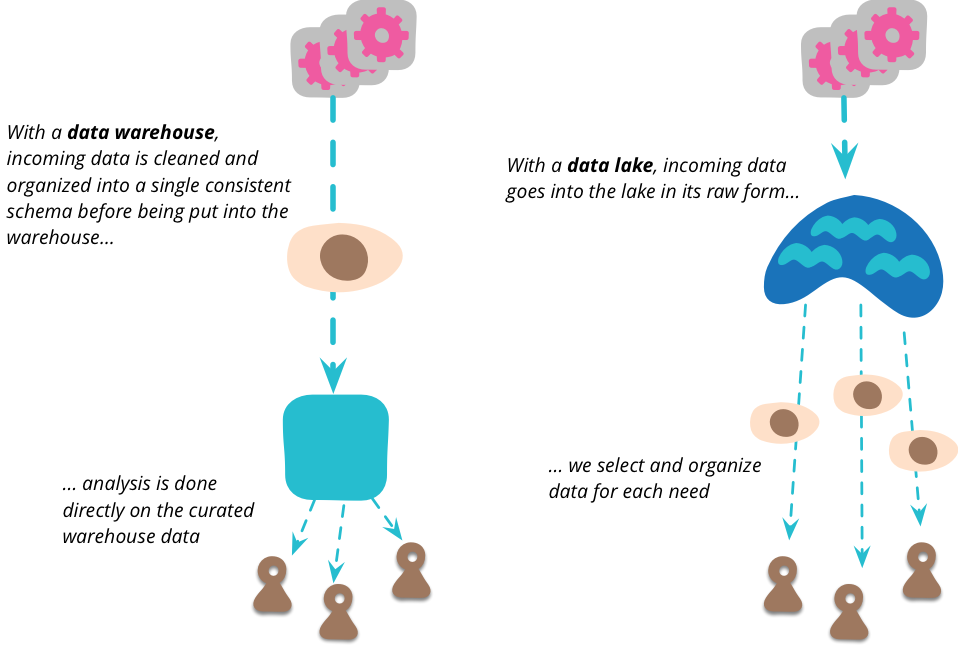
ผู้พูดเริ่มปูบทจากการเล่าการจัดการ Big Data ในปัจจุบันผ่าน Data Platform ต่างๆ โดยเริ่มจาก Data Warehouse ตั้งแต่ปี 1970s ซึ่งมี feature ครบตั้งแต่ extract-transform-load (ETL) ทำ data analytics จนถึง business report และ visualization ส่วนใหญ่ support SQL มี technology ที่ใช้ เช่น Google BigQuery Snowflake Power BI และ Tableau
ปัญหาคือการ maintain ที่ยากมาก การทำ table view และ report ที่รู้แค่ไม่กี่คน
ในปี 2010 ก็มีแนวคิดเรื่องของ Data Lake ขึ้นมา การใช้งาน data ที่เป็น schemaless ทำให้ลดการปวดหัวเรื่องของการ maintain ลง แต่อีกด้านนึงคือการจัดการกับ raw data เป็นเรื่องยาก ดังนั้นสำหรับ data ที่คนสนใจเยอะๆ เราก็ไม่ต้องการให้แต่ละคนเข้าไปจัดการ Data Lake ซ้ำๆ จึงมีการสร้าง Lake shore mart โดย data scientist จะรวบรวมและจัดการ data ออกมาจาก Data Lake ให้คนที่สนใจสามารถเข้าถึง data ได้ง่ายขึ้น (เปรียบเทียบกับการหาปลา แทนที่จะให้แต่ละคนไปตกปลาเอง เราก็ให้ชาวประมงมาตกให้ แล้วก็ไปซื้อต่อจากเค้าที่ตลาดปลาเอา) มี technology ที่ใช้ เช่น Hadoop และ Google Cloud Storage
 https://martinfowler.com/bliki/DataLake.html
https://martinfowler.com/bliki/DataLake.html
Data Lake ไม่ใช่คำตอบของทุกอย่าง โดยเฉพาะกรณีที่ context ของเราซับซ้อนไม่ชัดเจน เช่น นิยามของ Customer ระหว่าง ประกันชีวิต กับ ประกันภัย อาจจะต่างกันโดยสิ้นเชิงในอนาคต ทำให้การนิยามเพื่อสร้าง Lake shore mart มันซับซ้อนขึ้น สุดท้ายพอจะไปงมใน Data Lake เอง ก็ยากเข้าไปอีก
บทสรุปของปัญหาทั้งปวงคือ Scalability
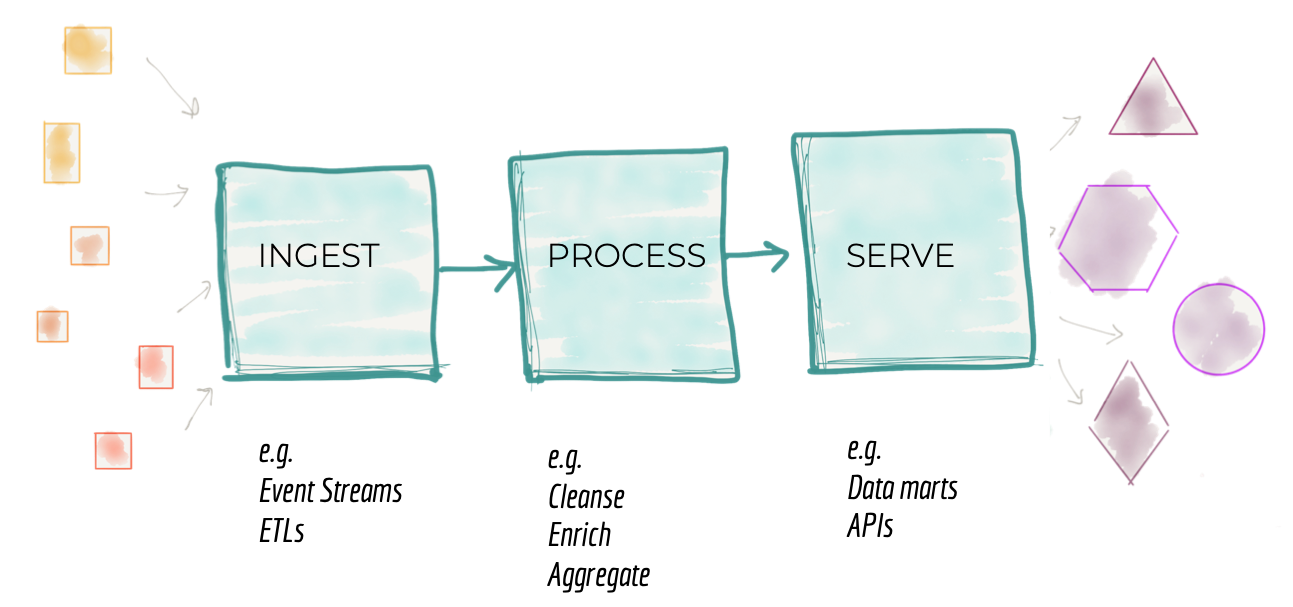
ไม่ว่าจะเป็น Enterprise Data Warehouse ที่เป็น monolith หรือ on-cloud data platform ที่แยกส่วนของการ ingest-process-serve ไว้อย่างชัดเจนเป็น data pipeline ก็จะพบปัญหาการ scale อยู่ดีเพราะเวลาเรา scale โดยการเพิ่ม product ใหม่ จำเป็นต้องแก้ทั้ง 3 ส่วน
ซึ่งพอมองย้อนกลับมาที่ organization structure อาจจะพบว่าแต่ละส่วนมีคนที่ชำนาญในแต่ละส่วนคอยดูแลเป็น silo อยู่แล้ว ทำให้เกิดอุปสรรคต่อ communication collaboration และ automation ด้วย (นี่มัน DevOps หรือเปล่านะ)
 https://martinfowler.com/articles/data-monolith-to-mesh.html
https://martinfowler.com/articles/data-monolith-to-mesh.html
แก้ปัญหาการ scale ด้วย Data Mesh
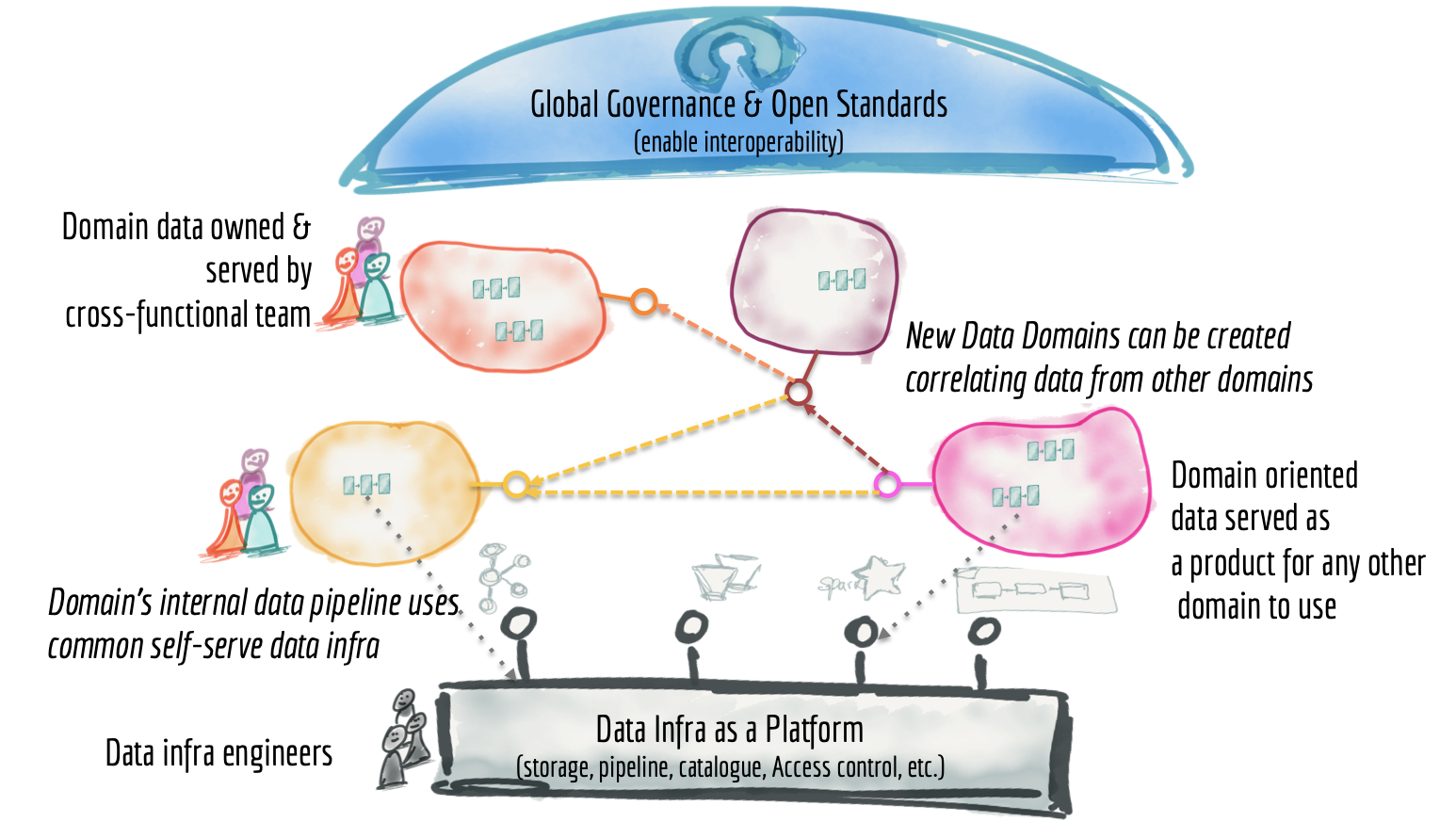
ผู้พูดอธิบายถึง Data Mesh ซึ่งก็คือการจัดการข้อมูลแบบ Big Data ในระบบ Distributed architecture แบ่ง product team ตาม data และแยกความซับซ้อนในการสร้าง product ให้ infrastructure team เป็นคนดูแล โดยประกอบไปด้วยหลักการ 4 ข้อ
- Distributed architecture
- Product mindset
- Self-serve
- Governance
 https://martinfowler.com/articles/data-monolith-to-mesh.html
https://martinfowler.com/articles/data-monolith-to-mesh.html
Distributed architecture
เราจะเปลี่ยนการ focus ที่ data pipeline ของเราเป็นที่ตัว data เนื่องจากการเปลี่ยนแปลง pipeline เกิดขึ้นเพราะ data ส่วน pipeline เป็นเพียงแค่ implementation เท่านั้น มีการนำ technique ที่เราอาจจะเห็นใน event-driven architecture มาบ้างแล้ว เช่น
- แบ่งการ ingest และ serve ตาม rate of change
- เก็บ data ส่วนของการ ingest เป็น event หรือ snapshot (immutable)
- เก็บ data ส่วนของการ serve เป็น historical data สำหรับการ replay
Product mindset
เนื่องจากเราเปลี่ยน mindset จาก project เป็น product ทำให้เกิดการเปลี่ยนแปลงใน organization structure เนื่องจากเราจะได้ทีมที่มีทั้ง data engineer data scientist และ business analyst มาอยู่ด้วยกัน ทำให้ทีมทำงานได้ดีขึ้น แต่ละทีมจะมี input source และ output source ของตัวเอง
ตัวอย่างที่น่าสนใจคือมี comment จากผู้ฟังเกี่ยวกับปัญหาที่เจอเมื่อทำ distributed data architecture คือเรื่องของ technology ที่ทีมส่วนใหญ่เลือกใช้ Microsoft Excel หรือ Microsoft Access ในการ ingest ประเด็นคือทั้งคู่ไม่สามารถรองรับการเปลี่ยนแปลงได้ตาม business ทันเท่ากับ platform ใหม่ๆ จนกลายเป็น legacy
จากตัวอย่างนี้ทำให้เราเห็นว่าเราต้องเลือก technology ที่ง่ายต่อการเปลี่ยนแปลง สำหรับ Microsoft Excel หรือ Microsoft Access เริ่มแรกมันใช้งานง่ายก็จริง แต่ทั้งคู่ไม่ใช่คำตอบในระยะยาว ตามเหตุผลข้างบน use case ที่เหมาะกว่าน่าจะเป็นการทำพวก exploration หรือ proof-of-concept (PoC) มากกว่า ดังนั้น technology สำหรับ production-grade ต้องสามารถ share data ที่สามารถ scale ได้ รวมถึงรองรับ versioning discoverability testing และ access control (มีคนพูดถึงเรื่องนี้ในหัวข้อ Democratizing programming)
Self-serve
เมื่อพูดถึง Distributed architecture เราจะต้องเจอกับ effort ในการสร้าง infrastructure ซ้ำๆ กัน เช่น การเตรียม component สำหรับ ingest-process-serve ที่เหมือนๆ กัน จึงมีการแนะนำให้มีทีมที่คอยช่วยเรื่อง infrastructure ให้กับ data product team เพื่อให้ทีมอื่นๆ focus กับ business logic ของตัวเอง ใน session ผู้พูดแนะนำ technology ต่างๆ เช่น
- Data provisioning engine (ช่วยสร้าง Data Lake หรือ Analytics platform ให้ product team)
- Data observability (monitoring, logging, alerting)
Governance
การ access data จากศูนย์กลางที่ๆเดียวจะเปลี่ยนเป็นหลายที่แทน ทำให้เกิดการเหลื่อมกันของ context ระหว่าง product หลายๆ ก้อน (polyglot) จึงต้องมีการกำหนด context ที่เป็นมาตรฐาน (standardized) และเป็นภาษาเดียวกัน (ubiquitous) ก่อน (ตรงส่วนนี้ต้องทำความเข้าใจเรื่อง domain-driven design เพิ่ม) แล้วใช้ technique ต่างๆ เข้ามาช่วย เช่น
- Identity management อย่างการใช้งาน Customer data ก็ต้องนิยาม Customer ใน scope ของ ประกันชีวิต กับ ประกันภัย ให้่เป็นสิ่งเดียวกัน
- Deduplication (canonical data)
ปิดท้ายด้วย Q&A ที่น่าสนใจ
Q: เราจะสร้าง report สำหรับ business อย่างไรใน Data Mesh ?
A: การสร้าง report จะอยู่ในส่วนของการ serve output ของแต่ละ product team ซึ่งจะทำเป็น event streaming เป็นแบบ near real-time หรือ business intelligence (BI) ที่ส่วนใหญ่รองรับ SQL interface อยู่แล้ว ส่วนใครสนใจ data จากหลายๆ polyglot ก็ไป aggregate จาก output เอา
Q: แล้วเราจะ track การเปลี่ยนแปลงของ data schema ได้อย่างไร
A: หนึ่งในวิธีที่ผู้พูดแนะนำให้ใช้คือการสร้าง REST API สำหรับแสดง schema มีทั้งชื่อ field และ data type ในเมื่อเรามี product mindset การดูแลรักษา API นี้ก็ไม่ต่างกับ data อื่นๆ
- เก็บ schema ของทุก version ที่ support
- ระวังในส่วนของ backward compatibility (breaking change)
- สำหรับ security ไม่แนะนำให้คนใช้ schema เข้าถึง file ตรงๆ
Q: มีความคิดเห็นยังไงกับ Software-as-a-Service (SaaS) หลายเจ้าที่ support integration กับ Data analytics อยู่แล้ว
A: ไม่ได้มีการจำกัดว่าไม่ควรใช้ SaaS แต่ให้ตัวอย่างมาคร่าวๆ ว่าระบบของเราควรจะ support กับอะไรบ้าง ตามนี้เลย
- Data Lake Storage
- Event streaming เช่น Apache Kafka และ Apache Pulsar
- Analytics platform เช่น Spark หรือ Databricks