บันทึกแนวคิดการแก้ปัญหา Datadog log/trace หายไปก่อนและหลังการ upgrade agent v7.35 ขึ้นไป
ช่วงต้นปีที่ผ่านมา ทีมเราที่ดูแล internal developer platform เจอปัญหาหนักใจมากเรื่อง trace กับ log ที่มันหายไปจาก Datadog โดยเฉพาะเวลา filter หาด้วย correlation ID แล้วไม่เจออะไรเลย ทั้งที่ระบบควรเก็บไว้ครบ เพราะงั้น blog นี้เราจะมาเล่าแบบเข้าใจง่าย ๆ ว่ามันเกิดจากอะไร แล้วทำไมวิธีแก้แบบ restart agent ถึงใช้ได้พักเดียว สุดท้ายต้องไปจบที่ config ของตัว tracer ต่างหาก
จุดเริ่มต้นของเรื่องวุ่น
ตอนแรก ๆ developer พบเจอปัญหาในการใช้งาน Datadog นาน ๆ ครั้งอย่างเช่น
-
Log และหรือ Trace หายจาก Datadog explorers อย่างไม่มีปี่มีขลุ่ย correlation ID (คร่าว ๆ ก็คือเป็น ID ที่สร้างขึ้นเพื่อเชื่อมว่า log นี้มาจาก trace ไหนและในทางกลับกัน trace นี้มี log อะไรเกี่ยวข้องบ้าง) ระหว่าง Trace กับ Log ใช้งานไม่ได้
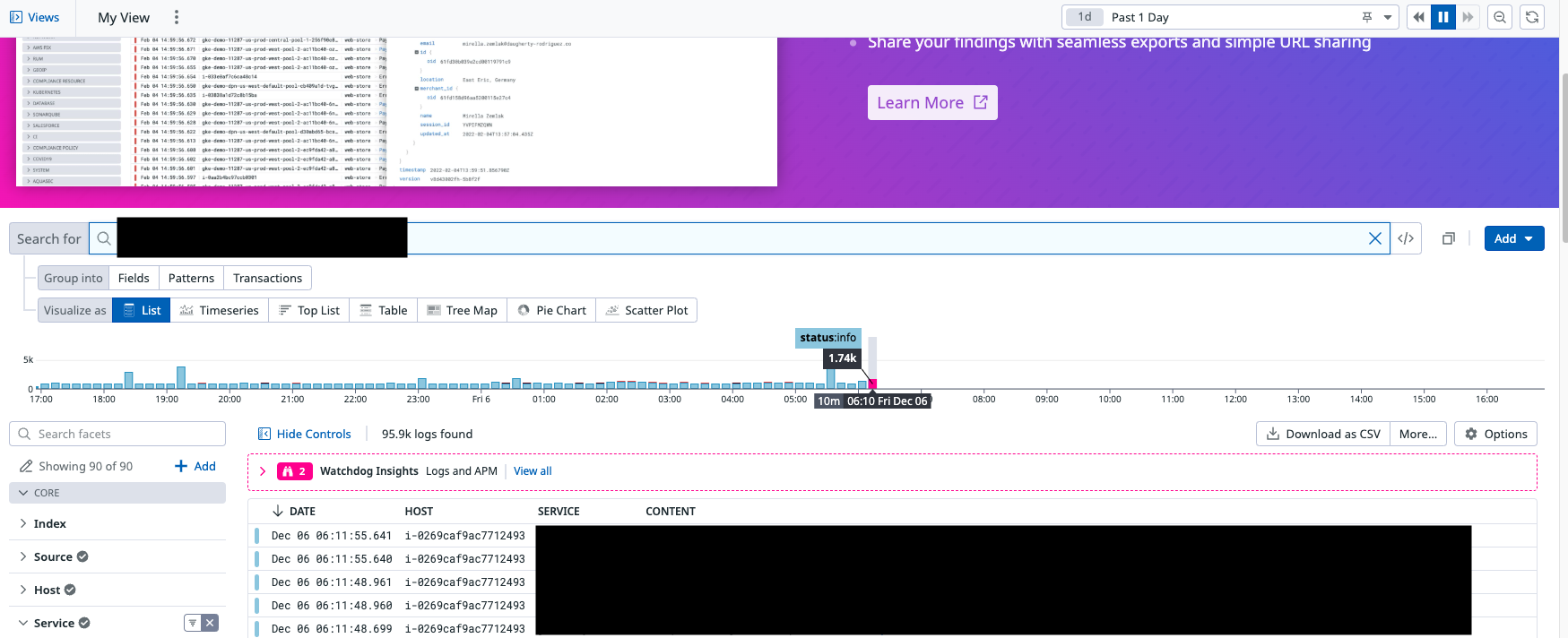
-
Metrics ของ orchestrator โผล่ไม่ครบ หรือบางทีก็ไม่แสดงผลเลย
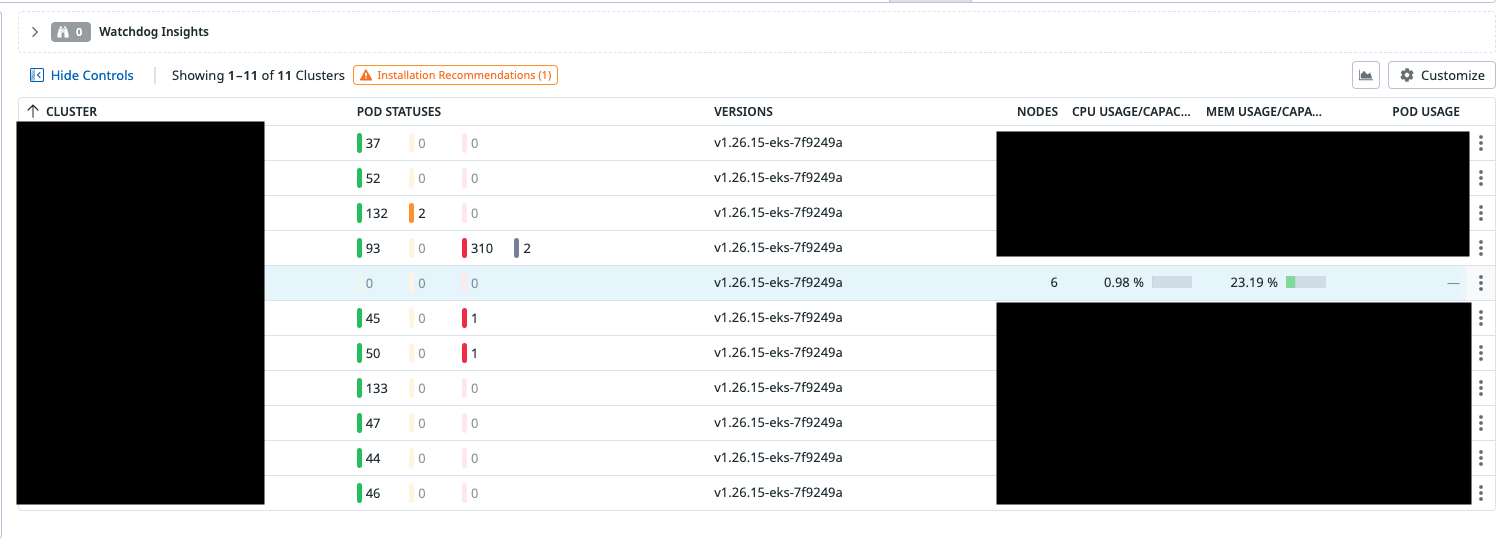
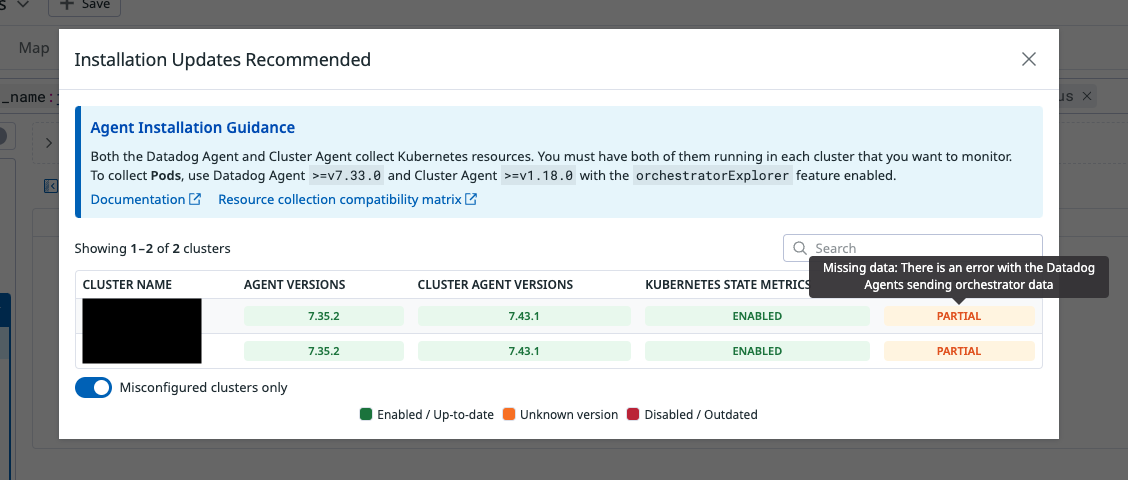
-
มี error หรือ warning ที่พบใน kubelet บาง node ซึ่งอาจมีผลต่อ agent communication
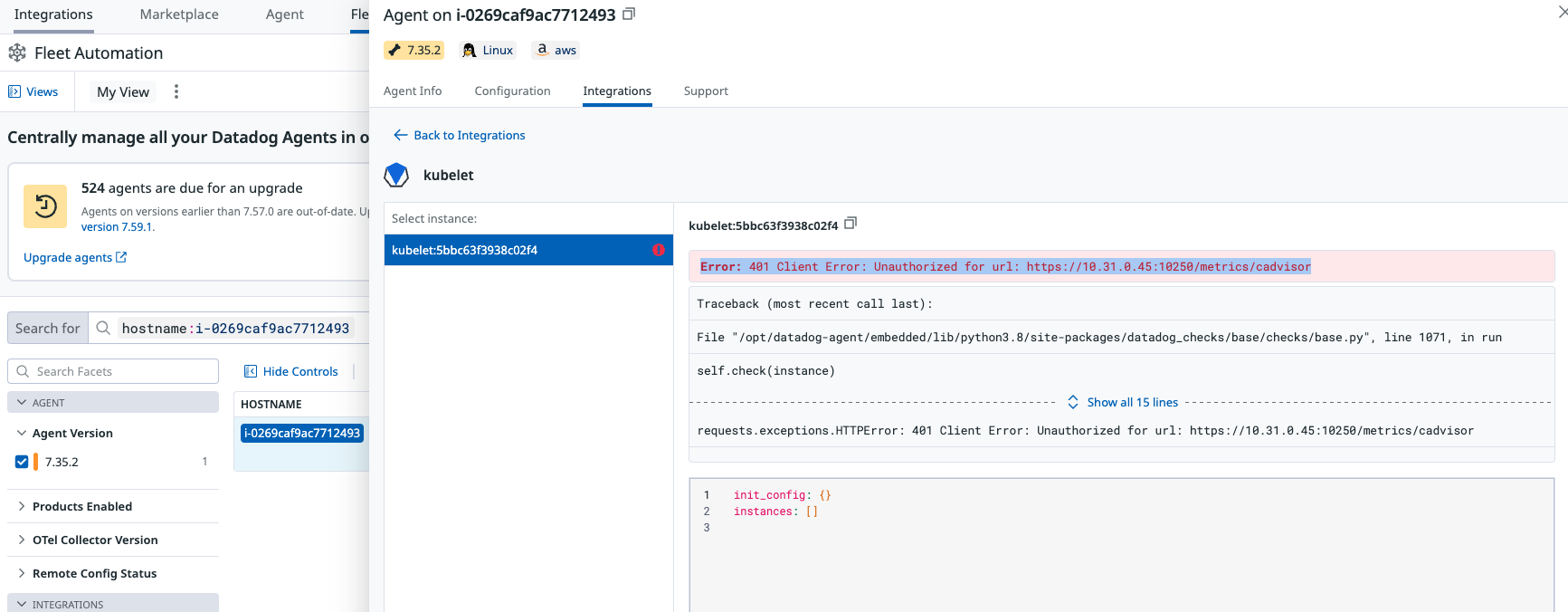
สาเหตุพวกนี้มันสร้างความไม่มั่นใจให้กับ developer มาก เพราะเวลาเกิด incident แล้วดู trace ไม่ได้ มันเหมือนมืดแปดด้านเลย
ซึ่งวิธีการที่เราเลือกก็คือ restart agent แล้ว log ก็กลับมา เหมือนจะดีขึ้น แต่พอผ่านไปสักพักก็กลับมาเป็นอีก แล้วก็ต้อง restart ใหม่ วนลูปแบบนี้ไปเรื่อย ๆ ซึ่งแน่นอนว่าไม่ใช่วิธีแก้ที่ดีในระยะยาวเพราะการพัฒนา software ไม่ควรหวังพึ่งโชคชะตาทุกครั้ง
ลองแก้ปัญหา ได้ปัญหาใหม่
จากข้อสังเกตว่าการ restart agent มันช่วยแก้ปัญหาได้แค่ชั่วคราว ดังนั้นเราเชื่อว่าปัญหามันต้องอยู่ที่ agent สิ ก็ตรงไปตรงมา
พอเรา upgrade agent version ใหม่ (อย่าง v7.64) แล้วปรากฎว่ามันก็ยังเกิดปัญหาอยู่ คราวนี้หนักกว่าเดิมคือ restart แล้วมันไม่กลับมาจ้า แปลว่า ปัญหาอยู่ที่ที่อื่นแล้วแหละ
แล้วปัญหาจริง ๆ มันคืออะไร
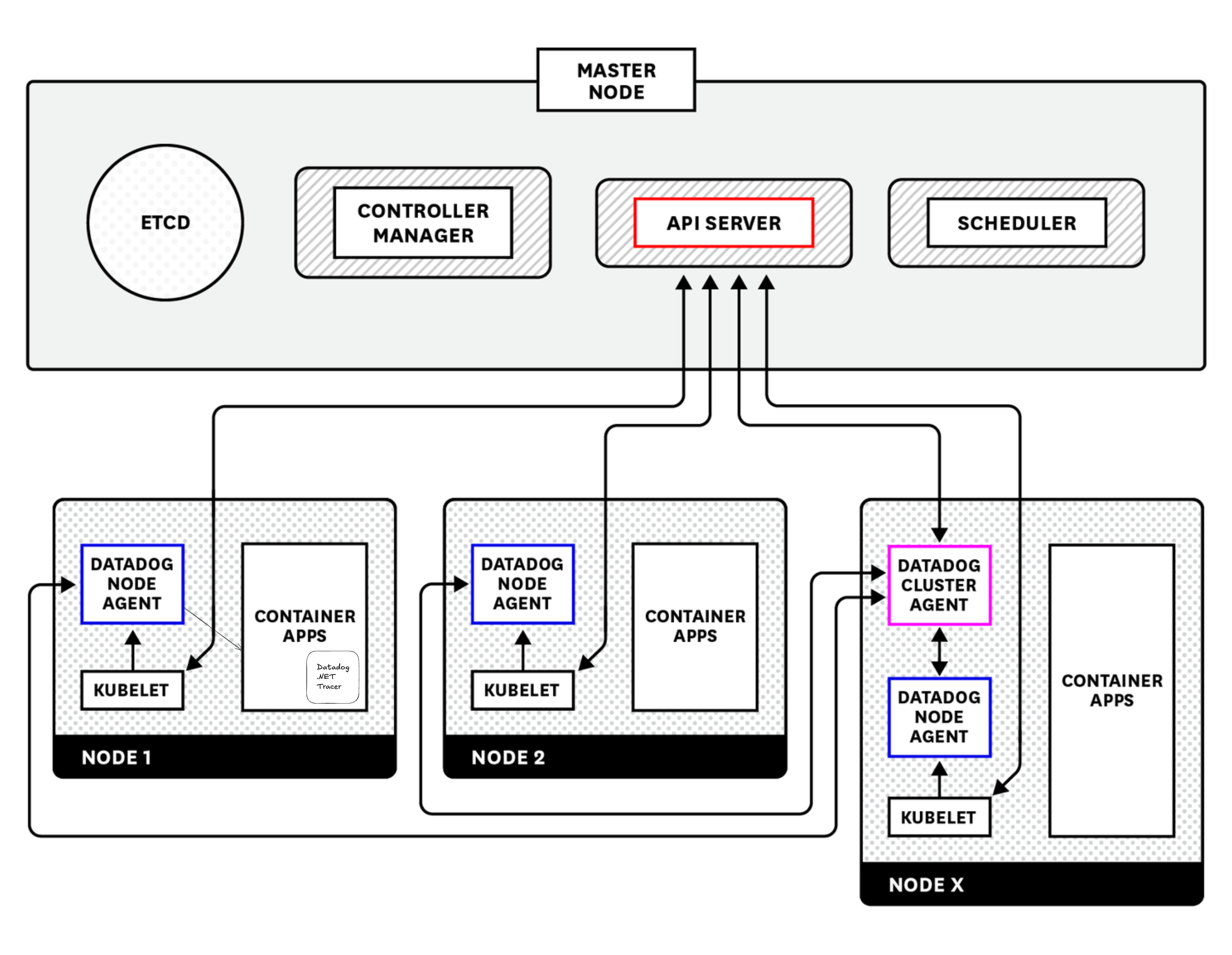
เพื่อจะเข้าใจว่าอะไรพัง เราต้องเข้าใจก่อนว่า Datadog มันทำงานยังไงในระดับโครงสร้าง
 https://www.datadoghq.com/blog/monitoring-kubernetes-with-datadog/
https://www.datadoghq.com/blog/monitoring-kubernetes-with-datadog/
-
Datadog Agent: ตัวนี้จะถูก deploy เป็น DaemonSet บน Kubernetes ทุก node มันเป็นคนเก็บ logs, metrics และ trace แล้วส่งขึ้น Datadog server
-
Datadog Cluster Agent: Deploy อยู่บน node ใด node หนึ่ง (ไม่ใช่ master) เอาไว้รวมข้อมูลระดับ cluster เช่น orchestrator metrics แล้วส่งต่อไปยัง Datadog server
-
Datadog Tracer: เป็น library ที่ฝังไว้ในตัว application ของเรา (มักติดตั้งผ่าน Dockerfile) หน้าที่หลักคือคอยสร้าง trace จาก request ต่าง ๆ แล้วตัดสินใจว่า trace ไหน “ควรส่ง” หรือ “ควรทิ้ง” ซึ่งอันนี้แหละคือพระเอกของเรื่อง
นำเสนอพระเอกของเรา Trace sampling decision
ในระบบที่มีปริมาณ traffic สูง การเก็บ trace ทุกตัวอาจทำให้เกิดภาระในการจัดเก็บและประมวลผลข้อมูล ดังนั้น Datadog Tracer จึงใช้กลไกที่เรียกว่า head-based sampling เพื่อตัดสินใจว่า trace ใดควรถูกส่งหรือทิ้ง โดยการตัดสินใจนี้เกิดขึ้นตั้งแต่ต้นทางของ request และถูกส่งต่อผ่าน HTTP headers ไปยัง downstream service ทั้งหมด
 https://docs.datadoghq.com/tracing/trace_pipeline/ingestion_mechanisms/?tab=java#head-based-sampling
https://docs.datadoghq.com/tracing/trace_pipeline/ingestion_mechanisms/?tab=java#head-based-sampling
ในกรณีของ HTTP ตัว Tracer จะพิจารณาข้อมูลจาก HTTP headers เช่น:
x-datadog-trace-id: รหัสประจำ tracex-datadog-parent-id: รหัสของ span ที่เป็น parentx-datadog-sampling-priority: ค่าที่ระบุว่าควรเก็บ (1) หรือทิ้ง (0) trace นี้
หาก header เหล่านี้มีค่าที่ไม่ถูกต้องหรือมี header อื่น ๆ ที่ไม่เกี่ยวข้องเข้ามาแทรก อาจทำให้ tracer ตัดสินใจผิดพลาดและทิ้ง trace ที่สำคัญไป
เริ่มต้นเจาะลึกไปที่ Tracer
หลังจากที่ทำ research เราคุยกับ Datadog support team เราก็เริ่มด้วยการเจาะลึกไปที่ Tracer มากขึ้นโดยเปิดใช้งาน debug log ของ tracer ช่วยให้เราสามารถตรวจสอบการทำงานภายในของ tracer ได้อย่างละเอียด และช่วยในการวิเคราะห์ปัญหาที่เกิดขึ้น
สำหรับ .NET Tracer เราสามารถเปิดใช้งาน debug log ได้โดยการตั้งค่า environment variable ลงไปใน container ที่ run application ของเรา
DD_TRACE_DEBUG=true
ต่อมาก็คือบอก Tracer ให้แสดงผลว่า Tracer ได้รับ headers อะไรบ้างโดยการตั้งค่า environment variable ลงไปใน container ที่ run application ของเราเช่นกัน
DD_TRACE_HEADER_TAGS=traceparent:traceparent_header,tracestate:tracestate_header,x-datadog-trace-id:x-datadog-trace-id,x-datadog-parent-id:x-datadog-parent-id
Tracer จะบันทึกข้อมูลการทำงานลงใน log ซึ่งจะช่วยให้เราทราบว่า Tracer ได้รับ headers อะไรบ้าง และตัดสินใจอย่างไรกับแต่ละ trace
เจอต้นตอของปัญหาแล้ว
2025-04-11 07:33:05.062 +00:00 [DBG] Span closed: [s_id: aa7bfd3c3fec7e65, p_id: 17485712010906211363, t_id: 0556539ad60643d27ccd3c7d06c337d9] for (Service: example, Resource: GET /example/endpoint, Operation: aspnet_core.request, Tags: [...])
Details:
TraceSamplingPriority: 0
จาก debug log ข้างต้นจะเห็นว่า TraceSamplingPriority ถูกตั้งค่าเป็น 0 ซึ่งหมายความว่า trace นี้จะไม่ถูกส่งไปยัง Datadog agent และจะไม่ปรากฏใน UI ของ Datadog
หลังจากที่ Datadog support team นำ log ไปวิเคราะห์ก็พบว่า มีบาง header ที่ไม่เกี่ยวข้องโผล่เข้ามาใน context (พวกที่ไม่ใช่ header ของ Datadog โดยตรง) มันเลยทำให้ tracer ตัดสินใจทิ้ง trace ไปเฉย ๆ เพราะงั้นพอเราไปค้น trace ก็เลยไม่เจอ trace เพราะ trace มันโดน drop ไปตั้งแต่ต้นน้ำแล้ว
ได้เวลาแก้ปัญหาสักที
สิ่งที่ต้องทำคือเพิ่ม environment variable ลงไปใน container ที่รัน application ของเราเพื่อบอก Tracer ว่าควรสนใจเฉพาะ header ที่เกี่ยวกับ Datadog เท่านั้น
DD_TRACE_PROPAGATION_STYLE_EXTRACT=datadog
พอใส่เข้าไปแล้ว Tracer จะไม่สนใจ header แปลก ๆ อีกต่อไป และจะตัดสินใจเก็บ trace ได้แม่นยำขึ้นมาก หลังจาก deploy Tracer เสร็จ พอ request ใหม่เข้ามา ปรากฏว่า trace กลับมาให้เห็นตามปกติแล้ว (ดีใจมากกกก)
เพื่อไม่ให้ปัญหาแบบนี้เกิดซ้ำโดยที่เราไม่รู้ตัว เราจึงตั้ง alert เพื่อ monitor การ ingest ของ log และ trace โดยเฉพาะในแต่ละ application เพื่อที่เราจะรู้ก่อน developer ว่า trace หาย เพิ่มความมั่นใจให้ทีม developer เวลา investigate ระบบ
สิ่งที่ได้เรียนรู้
- เมื่อเกิดปัญหา อย่าดูแค่ output ให้ reverse กลับไปทุกชั้นของระบบเพื่อหาสาเหตุจริง และทำความเข้าใจว่าระบบเบื้องหลังทำงานอย่างไร
- การแก้ปัญหาแบบพึ่งพาโชคคือสัญญาณของระบบที่ออกแบบไม่แข็งแรง อย่าปล่อยให้เป็นนิสัย แต่ให้จัดการ tech debt เพราะในฐานะ platform team ถ้า platform ไม่แข็งแกร่ง developer ก็ไม่มีความมั่นใจในการใช้งาน มีแต่เสียกับเสีย
- แม้จะมี support team หรือ documentation แต่ไม่มีใครรู้บริบทของระบบเราเท่าเราเอง ดังนั้นทักษะการ debug เบื้องต้นใน component ที่เราดูแลอยู่ให้เป็นถือเป็นเรื่องสำคัญ