ครั้งแรกกับการ upgrade EKS cluster
ในฐานะที่ทีมของเรารับผิดชอบด้านการพัฒนาและบริหารจัดการ infrastructure platform สำหรับ API service ของธุรกิจสายการบินในส่วนสำคัญ อาทิเช่น การจองตั๋วและการ checkin เราจึงต้องการให้ platform มีความเสถียร และมีความพร้อมที่จะรับมือกับการใช้งานอย่างต่อเนื่องอยู่เสมอ เพราะหากเกิดปัญหาอาจส่งผลโดยตรงต่อภาพลักษณ์และรายได้ของธุรกิจ
เบื้องหลังของ platform นี้ เราใช้ Amazon EKS (Elastic Kubernetes Service) ซึ่งเป็น managed Kubernetes service จาก AWS ที่ถูก provision ขึ้นผ่านเครื่องมือ Terraform แต่เมื่อช่วงปีก่อนเกิดเหตุการณ์ที่ Terraform state เกิดความเสียหายทำให้ไม่สามารถใช้จัดการ provisioning หรือแก้ไข cluster ได้โดยไม่สร้างความเสี่ยงต่อ API service (ล่ม) สิ่งนี้จึงกลายเป็นประเด็นที่ต้องหาทางออกในอนาคต
ตัดกลับมาที่ปัจจุบัน cluster ของเราใช้งาน Kubernetes version 1.23 มาเป็นระยะเวลาหนึ่ง และถึงแม้การใช้ version จะยังคงรองรับการทำงานของ platform แต่ AWS มีรอบการ release version ใหม่ของ EKS เป็นประจำ หากเราไม่ติดตามการ update เพื่อใช้งาน version ที่ใหม่กว่า
- อาจทำให้เราเสียโอกาสในการเข้าถึง feature ใหม่ ๆ ของ Kubernetes
- เป็นการเปิดโอกาสให้ช่องโหว่ด้านความปลอดภัยเข้ามาเสี่ยงกับ infrastructure ของเรา
- AWS มีแนวโน้มที่จะ upgrade cluster ให้อัตโนมัติเมื่อจำเป็น ซึ่งอาจเกิด breaking change ที่ทำให้ deploy API service ด้วย version ใหม่ไม่ได้
จาก challenge ที่เกิดขึ้น เราจึงตัดสินใจ upgrade cluster ของเราไปยัง version ที่ใหม่กว่า
แนวทางการ upgrade EKS Cluster
การเลือกวิธีในการ upgrade Cluster ของเราเป็นเรื่องที่ต้องพิจารณาอย่างละเอียดเนื่องจากการ upgrade ในระบบที่มีการใช้งานอย่างต่อเนื่องจำเป็นต้องจัดการเพื่อให้เกิด downtime น้อยที่สุด หลังจากที่เราได้ประเมินปัจจัยต่าง ๆ เราจึงกำหนดแนวทางการ upgrade ไว้สองวิธี ได้แก่ การแทนที่ Cluster เดิมด้วย Cluster ใหม่ (Cluster Replacement) และการ upgrade ใน Cluster เดิม (In-place Upgrade)
แนวทางที่ 1: Cluster Replacement
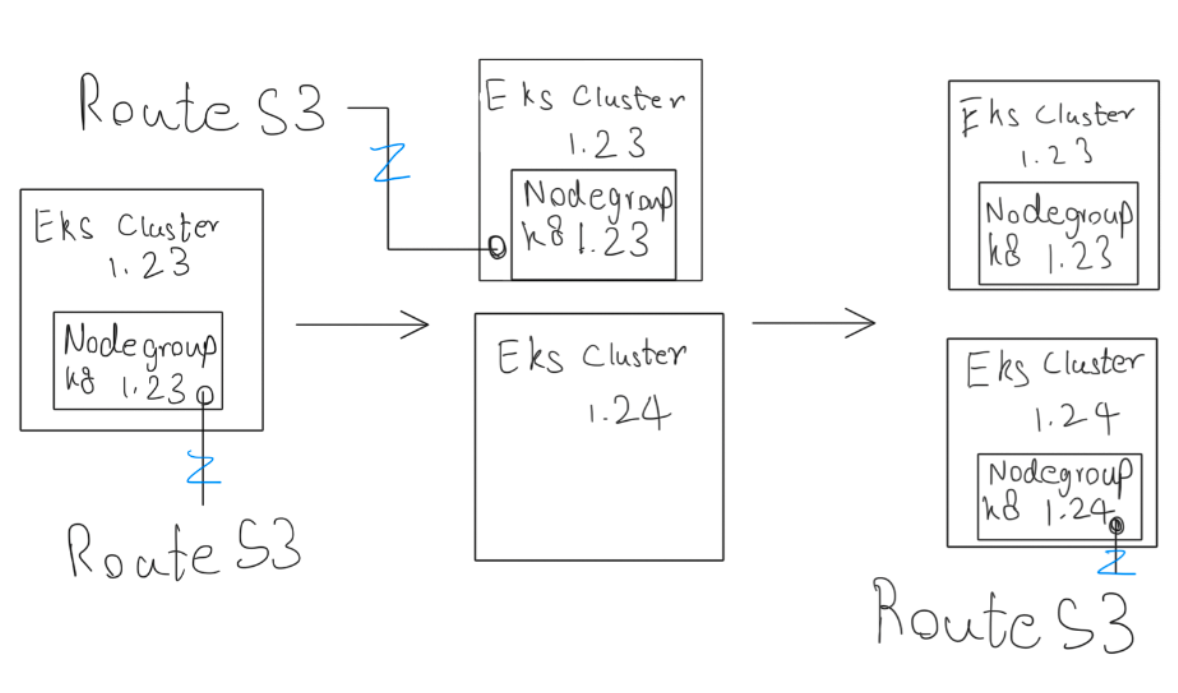
การแทนที่ Cluster เดิมด้วยการสร้าง Cluster ใหม่ หรือที่เรียกว่า Cluster Replacement เป็นการดำเนินการที่เราเริ่มต้นด้วยการตั้งค่า Cluster ใหม่ใน version ที่ต้องการ จากนั้นทีมเราทำงานร่วมกับนักพัฒนาเพื่อย้าย workloads ไปยัง Cluster ใหม่นี้โดยค่อย ๆ เปลี่ยนเส้นทางการจราจร (traffic) จาก Cluster เดิมไปยัง Cluster ใหม่แบบเป็นขั้นตอน ซึ่งกระบวนการนี้ช่วยให้เราสามารถตรวจสอบการทำงานของ workloads ที่มีการย้ายเข้ามาใน Cluster ใหม่ได้อย่างละเอียด
ข้อดีของ Cluster Replacement
- Cluster Replacement ทำให้เรามีโอกาสตรวจสอบความพร้อมของ services ที่ย้ายไปยัง Cluster ใหม่ได้อย่างเต็มที่ก่อนจะเปลี่ยนเส้นทาง traffic ของการใช้งานจริงไปยัง Cluster ใหม่ทั้งหมด หากเกิดข้อผิดพลาดระหว่างการย้ายกลับไปใช้ Cluster เดิมได้อย่างทันท่วงที
- Cluster Replacement ช่วยให้เราสามารถสร้าง Cluster ใหม่ใน version ที่ต้องการได้ทันที โดยไม่ต้อง upgrade ตามลำดับทีละ version
ข้อเสียของ Cluster Replacement
- การสร้าง Cluster ใหม่และย้าย workloads นั้นต้องอาศัยการวางแผน การประสานงาน และการทำงานร่วมกับทีมงานหลายฝ่าย โดยเฉพาะการเตรียมและสร้าง infrastructure ที่จำเป็น เช่น VPC, IAM roles, security groups ซึ่งถือเป็นภาระงานเพิ่มเติมและซับซ้อน
- Workloads ที่มี state หรือเป็น Singleton จะต้องมีการจัดการพิเศษในการย้ายไปยัง Cluster ใหม่เพื่อให้แน่ใจว่าไม่มีข้อมูลสูญหายหรือขาดตอน
แนวทางที่ 2: In-place Upgrade
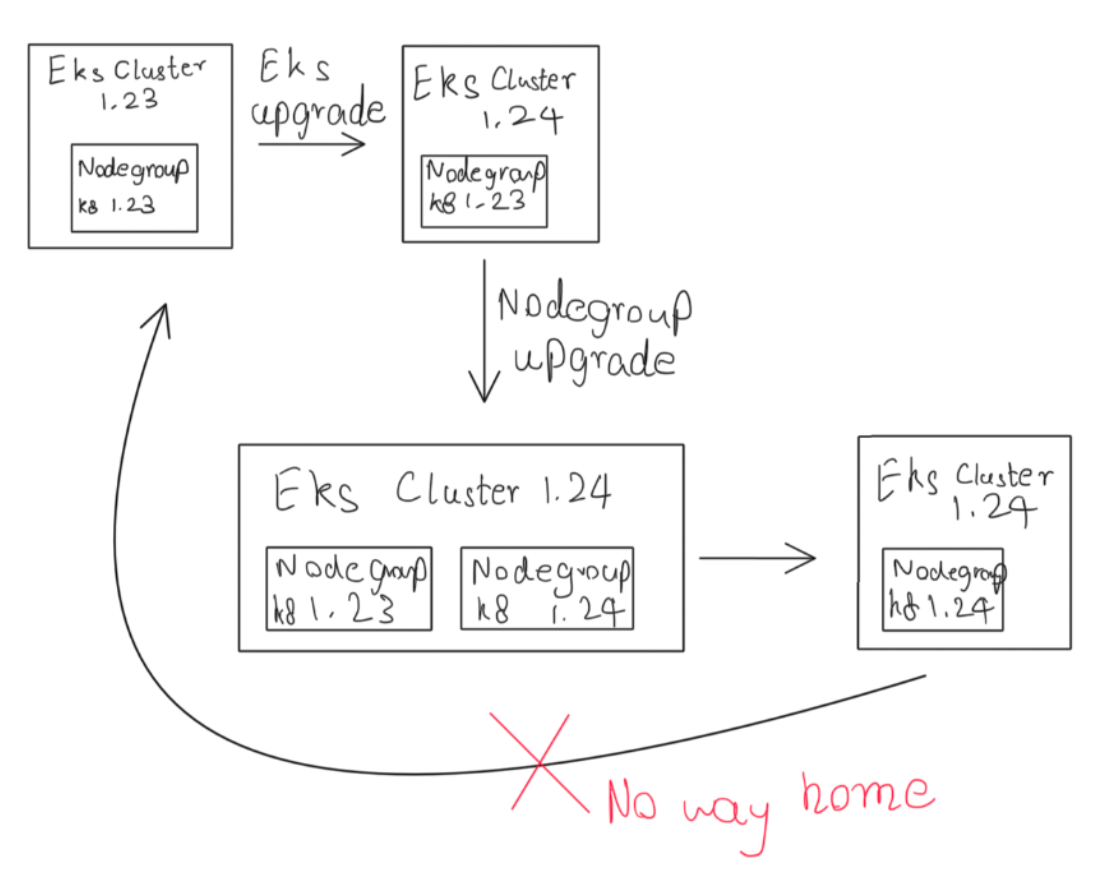
In-place Upgrade เป็นการ upgrade Cluster เดิมทีละ minor version เริ่มจากการ upgrade EKS control plane หนึ่ง version (เช่น จาก version 1.22 ไปยัง 1.23 จากนั้นเป็น 1.24) จนกระทั่งถึง version ที่ต้องการ วิธีนี้อาศัยการ upgrade ใน Cluster ที่ใช้งานอยู่โดยตรง ซึ่ง EKS มี feature ที่ช่วยในการทำ rolling updates เพื่อ upgrade API server nodes ไปยัง version ที่ทันสมัยโดยอัตโนมัติผ่าน eksctl
ข้อดีของ In-place Upgrade
- วิธีนี้ช่วยลดความซับซ้อนในการย้าย workloads และ infrastructure เนื่องจากไม่มีการย้าย workloads ไปยัง Cluster ใหม่
- ลด downtime ได้ดีกว่า Cluster Replacement เนื่องจากบริการใน Cluster เดิมยังคงทำงานได้ตลอดเวลาที่มีการ upgrade
ข้อเสียของ In-place Upgrade
- ไม่สามารถข้าม version ได้ ทำให้ต้อง upgrade ทีละ version ซึ่งใช้เวลานานและอาจเกิด downtime ได้หากมีปัญหาระหว่าง upgrade
- มีความเสี่ยงที่ workloads อาจทำงานผิดพลาดเนื่องจาก API deprecations ซึ่งทำให้ทีมงานต้องตรวจสอบว่า workloads ที่ใช้งานอยู่ไม่ใช้ API ที่จะถูกถอดออกใน version ใหม่ นอกจากนี้การ upgrade ทีละ node ยังต้องการเวลามากสำหรับ Cluster ขนาดใหญ่
จากการพิจารณาข้อดี-ข้อเสียของแต่ละตัวเลือกแล้วทีมเราตัดสินใจใช้วิธี In-place Upgrade ในการ upgrade ในครั้งนี้
ขั้นตอนในการทำ In-place Upgrade
- Pre-upgrade Checks: ก่อนเริ่ม upgrade เราจะตรวจสอบ compatibility ระหว่าง version ใหม่และ workloads ที่มีอยู่ โดยพิจารณา API deprecations ของ Kubernetes รวมถึงการตั้งค่า PodDisruptionBudgets เพื่อให้แน่ใจว่า workloads ที่มีจะยังคงทำงานได้
- Upgrade Control Plane: ทำการ upgrade control plane ให้เป็น version ที่ใหม่กว่าตามลำดับที่กำหนด
- Upgrade Worker Nodes: ดำเนินการเปลี่ยน worker nodes ทีละตัวไปยัง version ใหม่โดยใช้ rollout strategy ที่เลือกแบบ “one-node-at-a-time” เพื่อความปลอดภัยและลดผลกระทบต่อ workloads ที่ run อยู่ โดยที่เวลาในการ upgrade แต่ละ node นั้นถือว่ายอมรับได้สำหรับขนาดของ Cluster ที่เรามี
- Upgrade Cluster-addons: ทำการ upgrade Cluster-addons ผ่านการใช้ CodeBuild เพื่อ run script ต์ที่สร้างจาก Ansible โดยแบ่งเป็น 2 ประเภทใหญ่ ๆ คือ
- Default addons: VPC CNI plugin, kube-proxy, coredns
- External addons: cluster-autoscaler, kube-state-metrics, metrics-server, และ Datadog
- Post-upgrade Checks: ตรวจสอบ nodes, pods, network connectivity และรัน functional tests เพื่อให้มั่นใจว่า Cluster ทำงานปกติหลังจาก upgrade เสร็จสิ้น
เพื่อป้องกันปัญหาที่อาจเกิดขึ้นกับ workloads ของลูกค้า ทีมงานได้ใช้เครื่องมืออย่าง Pluto และ EKS upgrade insights เพื่อช่วยตรวจสอบ API deprecations และวางแผนการ upgrade ให้เข้ากับ workloads และ Cluster-addons ต่าง ๆ
แนวทางปฏิบัติเพื่อเตรียมความพร้อม
- การจัดอบรมภายในทีม: จัด mini-workshop เพื่อให้ทีมงานทุกคนเข้าใจถึงกระบวนการ upgrade และการรับมือกับปัญหาที่อาจเกิดขึ้น
- เริ่ม upgrade จาก environment ล่างสู่บน: เริ่ม upgrade จาก environment ที่มีผลกระทบน้อยก่อน เช่น DEV, UAT ไปจนถึง PROD เพื่อเป็นการทดสอบและเพิ่มความมั่นใจในกระบวนการ upgrade
- เตรียม script ที่ใช้งานซ้ำได้: เพื่อความสะดวกและลดข้อผิดพลาดจากการด upgrade ด้วยตนเอง
ความท้าทายและบทเรียนที่ได้รับ
- เนื่องจาก Terraform state ที่เราใช้เสียหาย ทำให้เราต้อง upgrade แบบอัตโนมือ (manual) ซึ่งนำไปสู่ความเสี่ยงที่อาจเกิดข้อผิดพลาด
- State ระหว่าง environment ต่าง ๆ ยังไม่เหมือนกัน เช่น เราพบว่า addons ที่ติดตั้งผ่าน Helm นั้นมีเพียงบาง environment เช่น DEV เท่านั้นที่รองรับ รวมไปถึงการตั้งค่า network ที่ไม่เหมือนกันในบาง environment ทำให้ API service ไม่สามารถเชื่อมต่อกับ third-party service ได้ จึงต้องการความช่วยเหลือจากทีมเพื่อนบ้านเพื่อแก้ไขปัญหาการตั้งค่า network ด้วย
- เมื่อ Kubernetes มีการ upgrade version ทุก ๆ ไม่กี่เดือน การเตรียมกระบวนการที่เป็นอัตโนมัติมากขึ้นเพื่อสามารถจัดการการ upgrade ได้อย่างรวดเร็วและแน่นอนมากขึ้นนั้นเป็นสิ่งสำคัญ
- การมีระบบ monitoring ที่ดีย่อมช่วยทำให้เราตรวจสอบว่าการ upgrade นั้นไม่มีผลกระทบต่อ API service