บันทึกการแบ่งปัน Four Key Metrics ให้เพื่อนๆ ในทีม
เมื่ออาทิตย์ที่แล้วผมกับรุ่นพี่อีกคนได้ทำการแบ่งปันเรื่อง Four Key Metrics ที่ไปอ่านเจอมาใน ThoughtWorks Tech Radar ก็เลยขอสรุปไว้ใน blog นี้ละกัน
เริ่มจากความหมายกันก่อน
จากงานวิจัย State of DevOps ที่ได้ตีพิมพ์ในหนังสือ Accelerate พบว่า คุณภาพขององค์กรมีผลเกี่ยวข้องกับคุณภาพของการส่งมอบ software โดยใช้เกณฑ์การวัด 4 ข้อได้แก่
Lead time for changes
ทีมของคุณใช้เวลาตั้งแต่เริ่มนำงานเข้ามาจนกระทั่งส่งมอบถึงลูกค้าเท่าไร หรือจะวัดเวลาตั้งแต่นำ code ขึ้น remote repository จนถึง deployment to production ก็ได้
เป้าหมายหลัก Communication และ Collaboration เนื่องจากการพูดคุยของคนที่เกี่ยวข้องในการพัฒนาชิ้นงานง่ายขึ้น มีเป้าหมายร่วมกัน ใช้ tool เดียวกัน ทำให้ส่งมอบงานได้รวดเร็วขึ้น
Deployment frequency
ทีมของคุณ deploy ระบบงานบ่อยแค่ไหนกัน สามารถวัดได้ทั้ง non-production และ production
สะท้อนให้เห็นถึง Integration และ Automation ปัญหาระหว่าง development และ operation น้อยลงเพราะมาทำงานร่วมกัน ทำให้การ integrate ส่วนงานต่างๆ ง่ายขึ้นตามไปด้วย สามารถแก้ปัญหาได้อย่างรวดเร็ว
Mean time to restore (MTTR)
เมื่อระบบงานเกิดปัญหา เช่น service outage ทีมของคุณใช้เวลาเท่าไรถึงในการแก้ไขให้ระบบกลับมาทำงานได้เหมือนเดิม
วัดในส่วนของ Automation เนื่องจากทีมที่ดีจะสร้างระบบอัตโนมัติเพื่อนำระบบงานกลับมา พร้อมทั้งส่ง notification ในรูปแบบต่างๆ ให้กับสมาชิกในทีมเมื่อระบบเกิดปัญหา
Change fail percentage
เมื่อนำระบบงานขึ้น production มีโอกาสที่ระบบจะไม่สามารถ deploy ได้หรือเกิด major issue ขึ้นกี่เปอร์เซ็นต์
เกี่ยวข้องกับ deployment frequency เพราะการที่เราจะส่งมอบงานบ่อยและมีคุณค่าต่อ business อย่างรวดเร็ว จะต้องลดความผิดพลาดลง
หลังจากวัดค่าได้แล้ว ก็นำมาเทียบกับตารางนี้
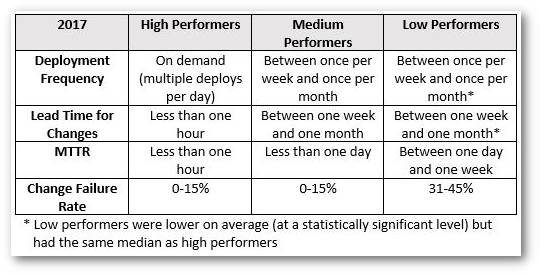
https://www.red-gate.com/blog/software-development/learning-from-the-accelerate-four-key-metrics
ถ้าไม่สามารถวัดได้ครบ 4 ข้อ
สามารถใช้ metrics เหล่านี้แทนได้เหมือนกันครับ
- Deployment size อาจจะดูจากจำนวน feature หรือ story หรือ bug ก็ได้ เล็กๆไม่เท่าไร แต่ต้องเท่าๆกัน
- Deployment time เวลาที่ใช้ในการนำระบบงานขึ้น non-production หรือ production
- Customer ticket ถึงแม้ bug จะน้อย แต่การที่ลูกค้าพบเจอปัญหาก่อนที่เราจะเจอ ลงเอยด้วยการโทรหรือเมลล์มาด่าเรา ไม่ดีแน่ๆ
- Defect escape rate จำนวน bug ที่เจอก่อน vs หลังผ่าน QA step ไป แสดงให้เห็นกระบวนการทดสอบ ทั้ง automated และ manual
- Availability ระบบงานของเราที่นำขึ้นไปมีคุณภาพไหม หรือมี mechanism ที่ช่วยให้ระบบ stable เมื่อเกิดปัญหาไหม
- Usage and traffic จำนวนการเข้าใช้งานที่โผล่มาตูมเดียวหรือไม่มีเลยเป็นสัญญาณถึงความผิดปกติของระบบ
- Error rate จากจุดที่ error มีจำนวนมากขึ้น ระบบต้องสามารถ trace กลับไปดูว่าเกิดขึ้นตรงไหน
- Performance สามารถค้นหาจุดผิดปกติหรือเป็นคอขวดของระบบได้ และลงมือแก้ได้ทันท่วงที
จากนั้นก็มา Take action กัน
- อธิบาย metrics เหล่านี้พร้อมทั้งที่มา วิธีคิดให้ทีมดูอย่างเปิดเผย เพื่อจุดประเด็นการพูดคุยกันอย่างตรงไปตรงมา ไม่เอาแบบว่าหาข้ออ้างเพื่อเพิ่มความชอบธรรมให้ความกากของตัวเองนะ ฮ่าๆๆๆ
- สรุปปัญหาและสาเหตุที่ทำให้ตัวเลขออกมาเป็นแบบนั้น
- เลือกปัญหาที่ต้องการจะแก้ไขมา 1 อย่าง ตั้งเป้าหมาย จากนั้นพูดคุยเพื่อหาแนวทางการแก้ไขหรือปรับปรุงให้ดีขึ้น
- หลังจากได้ทำไปแล้ว ก็เก็บข้อมูลขนาดเดียวกันแล้ววัดใหม่ เปรียบเทียบกับของเก่าเพื่อรับ feedback ต่อไป
- กลับไปที่ข้อ 3 ทำแบบนี้ไปเรื่อยๆ เป็น feedback loop ปรับปรุงให้ดีขึ้นอย่างต่อเนื่อง
ข้อควรระวัง
- อย่าไปเคร่งกับ High, Medium, Low มากแบบว่าต้องแข่งกันกับทีมอื่นขนาดนั้น เอาไว้วัดกับตัวเองอยู่จุดไหน เพื่อหาจุดปรับปรุงให้ดีขึ้นจะดีกว่า
- อย่าแลกในส่วนของ Quality เพื่อให้ได้ตัวเลขที่ดีขึ้น เช่น เอาชุดการทดสอบออกเพื่อให้ผ่าน เป็นต้น เพราะมันไม่ช่วยทำให้ดีขึ้นจริงๆ
สิ่งเหล่านี้จะไม่มีประโยชน์เลย ถ้าเราไม่ยอมรับก่อนว่าเรามีปัญหาอะไรบ้าง
Reference: 15 Metrics for DevOps Success