สรุปสิ่งที่ได้เรียนรู้เกี่ยวกับ Elasticsearch ปี 2021 (Part 2)
ใน part นี้จะมาเน้นในส่วนของ Scaling และ Best practices ในการเตรียมความพร้อมใช้งานในระดับ production grade
Configuration
- ตั้ง
bootstrap.memory_lockเป็นtrueเสมอ เพื่อช่วยเพิ่ม performance เนื่องจาก Elasticsearch มันจะทำ JVM swap memory ในกรณี physical memory หลักใกล้เต็ม มันก็จะย้ายไปไว้ใน virtual memory แทน ซึ่งมันเปลือง performance เมื่อเทียบกับ availability ที่ได้ (ดูจาก Official guideline ได้) - ตั้งหรือเปลี่ยน
cluster.nameเป็นอย่างอื่นที่ไม่ใช่elasticsearchเนื่องจาก Node อาจจะ join กันข้าม cluster เพราะชื่อเหมือนกัน - การตั้งค่า
network.hostที่ไม่ใช่localhostทำให้ Elasticsearch เข้าสู่ production mode - การตั้งค่า Discovery จาก
discovery.seed_hostsและ JVM ต่างๆ เช่น Heap size (-Xmsและ-Xmx), GC logging ดูได้จาก https://www.elastic.co/guide/en/elasticsearch/reference/current/important-settings.html - การตั้งค่า
node.rolesให้เหมาะสม เช่นmasterหรือdataหรือingestดูได้จาก https://www.elastic.co/guide/en/elasticsearch/reference/current/modules-node.html
การ Query และ Filter
- Filter ก่อน แล้วค่อย query documents ที่เหลือ เพื่อ performance ที่ดี
- ถ้าต้องการ dump ข้อมูลใหญ่ๆ ใช้ Scan และ Scroll API
- เลือกเฉพาะ field ที่จะต้องใช้งานเท่านั้น
การจัดการ Sharding และ replication
- แต่ละ index จะมีอย่างน้อย 1 primary shard เสมอ ถ้าสมมติเรามี node เดียวแล้วดูไม่มีวี่แววว่าจะโตนะ ก็มีแค่ shard เดียวพอละ เปลืองเงิน
- เมื่อ set จำนวน shard แล้ว ไม่สามารถเปลี่ยนได้ ถ้าอยากเปลี่ยนก็ต้องสร้าง index ใหม่ด้วยจำนวน shard ใหม่แล้วค่อยย้าย Document ไปที่ index ใหม่ ผ่าน Reindex API
- การที่เรามี shard เยอะใน node เดียวช่วยทำงานแบบ parallel ได้เร็วขึ้นก็จริง แต่ performance ก็จะด้อยลง เพราะยิ่ง shard เยอะ segment ก็เยอะตาม ยิ่งต้องใช้เวลารวมเยอะ รวมถึง traffic network ก็เยอะตามด้วย
# nodes = ((primary shard + # replication shard) /2) + 1
การจัดการ Index และ mapping
- ใช้ Bulk API เพื่อเพิ่ม performance ในการ indexing (ระวังเรื่อง transaction ด้วย)
- หลีกเลี่ยงการใช้งาน Default mapping เพราะ default type เป็น
textกับkeywordซึ่งกิน memory กับ CPU - สำหรับข้อมูลใหญ่ๆ ให้เพิ่ม refresh interval และจำนวน replica ลง มันเปลืองน่ะ
- สำหรับข้อมูลจำนวนเยอะๆ (เช่น log) ให้ตั้ง retention period เพื่อลบวันที่เราไม่ต้องการออกไป
- ในกรณีที่ routing ปกติแล้ว performance ต่ำ เนื่องจาก จำนวน shard เยอะๆ สามารถสร้าง custom routing เพื่อกำหนดให้ข้อมูลลงไปใน shard ที่ต้องการได้ โดย
shard_num = hash(_routing) % num_primary_shards
- Log ช้า ในเพิ่ม settings ใน Index ตามนี้ https://www.elastic.co/guide/en/elasticsearch/reference/current/index-modules-slowlog.html
ปิดท้ายด้วย ELK stack
จริงๆ แล้วเราสามารถส่ง data ลงไปใน Logstash ได้ตรงๆ เลย แต่มันก็เสียเวลามา set logstash.conf หลายๆ อัน ปัญหานี้สามารถแก้ได้โดยการใช้ Beats ซึ่งรองรับหลาย format แต่ปัญหาที่ตามมาคือเรื่องของ resilency และ scalability เราสามารถใช้ Redis หรือ Kafka เป็น buffer สำรองข้อมูลได้ เมื่อเกิดปัญหาเรื่องข้อมูลหาย เราก็สามารถกลับมา replay ได้เลย
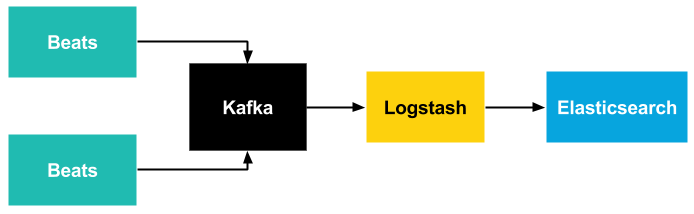 https://www.syslog-ng.com/community/b/blog/posts/logging-to-elasticsearch-made-simple-with-syslog-ng
https://www.syslog-ng.com/community/b/blog/posts/logging-to-elasticsearch-made-simple-with-syslog-ng