สรุปการแบ่งปันในทีมเรื่อง Monitoring ระบบด้วย Prometheus และ Grafana
เมื่ออาทิตย์ที่แล้วผมไปแชร์ให้ทีมเกี่ยวกับการ monitoring ระบบงานง่ายๆ ด้วย Prometheus และ Grafana คร่าวๆ มีประมาณนี้
เริ่มจาก How it works กันก่อน
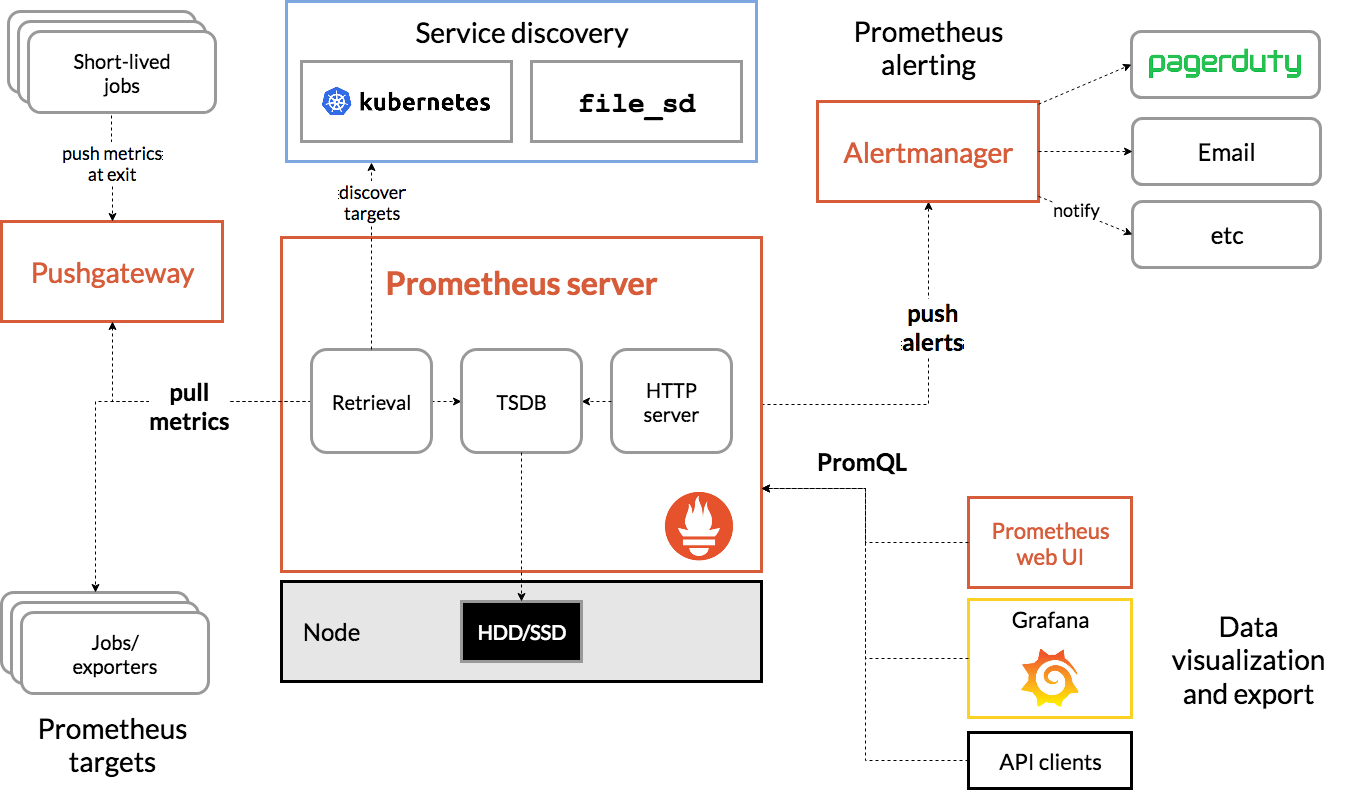
https://prometheus.io/docs/introduction/overview/#architecture
Prometheus ไปหา service ในระบบเราผ่าน service discovery (ในตัวอย่างใช้ Kubernetes) และไปดึง metrics จาก jobs หรือ metrics exporter ที่เราสร้างไว้ใน service นั้นๆ (ตัวอย่างเช่นการใช้ actuator และ micrometer ใน Spring) เอามาเก็บไว้ในรูปแบบของ time series (TS) และ Grafana ก็มา query database ผ่าน PromQL (Prometheus query language) เพื่อนำไป visualize เป็นตัวเลขหรือ graph ต่อไป
แล้วทีมเลือก metrics อะไรมา monitor บ้างล่ะ
จุดประสงค์ที่เราสร้างระบบ monitor ขึ้นมาเพื่อเป็นข้อมูลเพื่อ
- ช่วยตัดสินใจว่า ระบบที่เราสร้างขึ้นมานั้นมาถูกทางหรือไม่ ทั้งในมุมมองของ business และ technical
- ช่วยค้นหาจุดบกพร่องของระบบ หรือคอขวดที่ทำให้ระบบทำงานช้า
- ช่วยเตือนทีมเมื่อระบบเกิดปัญหาขัดข้อง ทำให้ทีมมีโอกาสรู้ปัญหาก่อนที่ลูกค้าจะรู้
ดังนั้น metrics ที่เลือกมาต้องมีสามารถตอบจุดประสงค์เหล่านี้ ตัวอย่างเช่น
- Service status เป็นเรื่องพื้นฐานมากๆ ว่าระบบเรายังอยู่ดีหรือไม่
- Availability และ downtime ของระบบ สะท้อนถึงคุณภาพชิ้นงานที่เราส่งมอบ
- Error rate เพื่อเป็นข้อมูลเบื้องต้นในการ trace ไปถึงการทำงานของระบบที่ผิดพลาด
- Usage และ traffic เพื่อดู trend ของแต่ละ feature ที่เราส่งมอบไป
- Response time สะท้อนถึง performance และ user experience ที่ลูกค้าประสบเจอ
พูดถึง Grafana กันบ้าง
ส่วนประกอบหลักๆ ของ Grafana ก็จะมี
- Dashboard แสดงข้อมูลที่เก็บมาเป็น graph single-stats หรือ table ก็ได้ สามารถทำ versioning ได้ด้วย
- Datasource รองรับทั้ง Prometheus และ Elasticsearch และอื่นๆ อีก (จำไม่ได้ ไปดูในนี้ ฮ่าๆๆ)
- ระบบ Alerting ตาม rule ที่เรากำหนดไว้ เช่น response time ไม่ควรจะเกิน 2000ms เป็นต้น ถ้าเกินก็ส่ง message มาบอกทีม ประมาณนั้น
ข้อควรระวังเกี่ยวกับ Time series
เนื่องจาก Prometheus เก็บข้อมูลในรูปแบบของ time series ดังนั้น Prometheus ไม่ได้เกิดมาเพื่อเก็บข้อมูลแบบสะสม (accumulated data) เช่น จำนวน usage ทั้งหมดตั้งแต่ระบบเคยมีมา feature ของ prometheus ที่สามารถแทนที่ได้คือ aggregation_over_time ซึ่งจะเป็นการเก็บแบบนับย้่อนหลังไปตามช่วงเวลา เช่น response time โดยเฉลี่ยภายใน 1 สัปดาห์
ปัญหาที่เคยเจอ
เนื่องจากการที่ Grafana query ข้อมูลมาจาก Prometheus ฉะนั้นถ้ามีการ process ข้อมูลหนักๆ เช่น ข้อมูลที่ต้อง calculate ย้อนหลังไป 1 ปี ภาระจะไปตกอยู่กับ CPU ของ Prometheus server ทำให้มีโอกาสที่ Prometheus จะล่มหรือส่งผลลัพธ์มาช้ากว่าปกติได้ ทั้งนี้ก็ขึ้นอยู่กับ configuration ที่เราบอกให้ Grafna ไปดึงข้อมูลมาทุก ๆ กี่วินาทีด้วย (interval)
ลองเอาไปใช้กันดูครับ ง่ายและมีประโยชน์มากๆ ส่วนใครอยากลองไปเล่นคร่าวๆ ก็เข้าไปใน Grafana Playground ได้เลย